[Article] Dynamic Discovery of Broker Nodes and Load Balancing in a Cluster

- Sidath Weerasinghe
- - WSO2
Discovery mechanisms could be broadly divided into two categories, namely static discovery and dynamic discovery. In relevance to servers, the static discovery uses an explicit list of server URLs to specify the available servers in a cluster. In this method, servers won't discover each other. The client only knows about the servers that are hard coded so the developer needs to know all the details of and configure each server. With this static discovery method, the developer cannot achieve auto scaling and load balancing in the cluster. This article mainly focuses on how WSO2 Message Broker (whose functionality is now integrated to the WSO2 Enterprise Integrator) nodes could be discovered dynamically.
Dynamic discovery
One of the problems engineers face when designing and developing distributed systems is dynamically discovering nodes in the distributed environment. There are numerous solutions to dynamic discovery in the distributed environment. It can be avoided entirely by hard coding (or configuring) the network architecture so discovery is done by the client manually. That is not practical because when scaling the distributed environment the client will want to restart their service and reconfigure it. By using dynamic discovery the user can achieve auto scaling and dynamic load balancing features.
For example, there are three message broker nodes in clusters (MB1, MB2, MB3). The client knows only node MB1. So the client asks to make a connection to MB1. MB1 verifies the client connection and allows the client to connect to it. Then MB1 tells the client there are several message brokers in the cluster such as MB2 and MB3. MB1 also tells all the other nodes that the client is connected to the MB1. After this simple routine, all the brokers know about the client and the client knows about all the nodes in the cluster. Now let's say the subscriber client also joins the network and asks to connect to MB3 subscribe to a topic 'foo'. Then the subscriber client knows all about the other message broker nodes like MB1, MB2 and MB3. The publisher client makes a connection with MB2 and messages are published to the topic 'foo'. The publisher client publishes the messages and the subscriber client gets them.
If MB3 crashes the client notices that MB3 isn't subscribing to messages any more since nodes MB1 and MB2 are up and running. Then the subscriber client automatically failover to another node in the cluster. Within this time, other clients can only make a connection the two running brokers in the cluster. After a short period, MB3 recovers and rejoins the cluster. The up and running client notifies the new broker to add to the cluster. Then the other nodes know that the MB3 is up and running. Now when a new client connects to any node of the cluster that the client knows that all the MB1, MB2 and MB3s are in the cluster. Therefore the mentioned scenario reveals a significant use case of dynamic discovery of nodes. There are a bunch of servers (cluster), only known for one or more (at least 3 are mostly recommended if one has crashed and is failover) and make a connection and to get some more information about other nodes. Then the client listens to status information or requests one of the servers to keep the client application informed about the events of joining and leaving of servers from the cluster network.
Load balancing
Distributed computing still has some limitations in certain features like load balancing. Load balancing is the concept of dividing the workload within two or more servers. Usually, load balancing is the main reason for server clustering in the distributed environment. Load balancing facilitates the developer to distribute client connections across multiple servers in the cluster and improve server fault tolerance. It distributes client requests throughout multiple servers in the cluster to optimize resource utilization. In a situation where a small number of servers in the cluster need to provide services to a huge number of clients, a server can become overloaded and its performance can go down. The concept of load balancing is used to prevent bottlenecks by forwarding the client connections among two or more servers in the cluster.
Round robin DNS algorithm for load balancing
The round robin DNS algorithm works based on a rotation. One server's IP address is offered when the client request comes in. It then moves the given IP to the back of the IP address list. Another client request comes to the server and the next server IP address is offered to that client, then it moves to the end of the IP address list and so on depending on the number of servers being used. Round robin DNS algorithm is usually used for balancing the load of distributed servers in a cluster with a large number of clients.

Figure 1
The main advantage of the method is its high availability through failover. Failover happens (server lost connection, server shutdown or server kills) when one node in a cluster cannot process a request and redirects it to another. Using this method the developer can find which brokers are added to cluster dynamically. This kind of feature is called auto scale.
The existing method
The message broker provides means to horizontally scale between nodes. The client which communicates with the broker is notified on the availability of the broker nodes in the cluster via JMS connection URL, which allows defining of a failover string (the list of IPs of the broker nodes separated by comma).
In JMS clients there is a method to create connection URL for subscribing and publishing messages.
private String getTCPConnectionURL(String username, String password) {
// amqp://{username}:{password}@carbon/carbon?brokerlist='tcp://{hostname}:{port}'
return new StringBuffer()
.append("amqp://").append(username).append(":").append(password)
.append("@").append(CARBON_CLIENT_ID)
.append("/").append(CARBON_VIRTUAL_HOST_NAME)
.append("?brokerlist='tcp://").append(CARBON_DEFAULT_HOSTNAME)
.append(":").append(CARBON_DEFAULT_PORT).append("'")
.toString();
}
The typical approach would require the user to manually list out IPs of the broker nodes in the cluster to the client connection string or the application context, which in fact limits the user experience and scalability goals in the following way:
- The user/developer manually listing out the IPs in the connection URL can cause errors. The user/developer can mislead the IP address and other details on the URL.
- The change of broker node IPs would require reconfiguring and restarting the client applications connected to it. If a new broker joins to the cluster then you need to shutdown a and then modify the configuration.

Figure 2
The proposed solution
- Specify an admin service inside the message broker where the broker clients can query the service to get the list of IPs in the broker cluster.
- Can discover the message broker nodes in the cluster by calling an admin service which is implemented inside the broker.
- Periodically calling this service we can get the dynamically added broker node IP addresses and can remove disconnected IP addresses from the list. It will always shuffle the IPs and provide it for the client.
- Based on the live message broker node IP addresses connections will be created in a round robin fashion for load balancing purpose.

Figure 3
Implementation
OSGI implementation
In the message broker the client can configure the AMQP address in the broker.xml.
<bindAddress>ip address</bindAddress>
But some client make it as 0.0.0.0. When the client set does this it binds to all the interfaces in the node.
Local cluster implementation
If the client configured bind address is “0.0.0.0” then they get all their interfaces IP address and interface name. Example - wlp3s0=10.100.4.165
For that we wrote an OSGI service and inside that service gets the AMQP port, AMQP SSL port, node identifier and all the IP addresses. After that it puts those details into the database and sends a hazelcast notification. This default OSGI bundle pack comes with WSO2 Message Broker.
AWS cluster implementation
AWS is very different from local cluster implementation. Using local cluster implementation the developer cannot get the AWS instance IP address. In AWS ec2 instance has two different IP address. The first one is a private IP address which is used for internal communication within ec2 instance. If the client is outside the ec2 instance then they need the ec2 public IP address to make a connection with the server. Using ec2 metadata API you can get those IP addresses and other details read from the configuration.
Like this, the developer can write an OSGI component to any other platform and get the suitable IP address for that (example - Openstack).
Web service implementation
Write an admin service to get the IP address, AMQP port and AMQP SSL port details at the carbon business module. Inside that the web service gets those details and makes an XML structure to arrange it in an easy to understand manner.

Figure 4
The web service result is as follows:
<IpList>
<node id="NODE:10.100.4.165:4000">
<addresses>
<address ip="10.100.4.165" port="5672" ssl-port="8672" interface-name="wlp3s0"/>
<address ip="192.168.11.50" port="5672" ssl-port="8672" interface-name="enp0s25"/>
</addresses>
</node>
<node id="NODE:10.100.4.166:4000">
<addresses>
<address ip="10.100.4.166" port="5672" ssl-port="8672" interface-name="wlp3s0"/>
</addresses>
</node>
</IpList>
For that service, introduce a new permission on the permission tree named “dynamicDiscovery”. If the client has that permission they can call this web service.
Client implementation
In Andes client, we implemented a new initialContextFactory and inside that, we made an AMQP URL using the result of the web service.
Inside the Andes client, you can call the web service to get the cluster node IP address and ports details. When calling the web service it shuffles the IP address and gives it to the client. Using this, create an AMQP URL inside the Andes client. Put the IPs as a failover. Periodically call the web service and update the broker list. Then the client can detect new brokers that are connected to the cluster when the cluster is running.
How to achieve dynamic discovery using WSO2 andes client
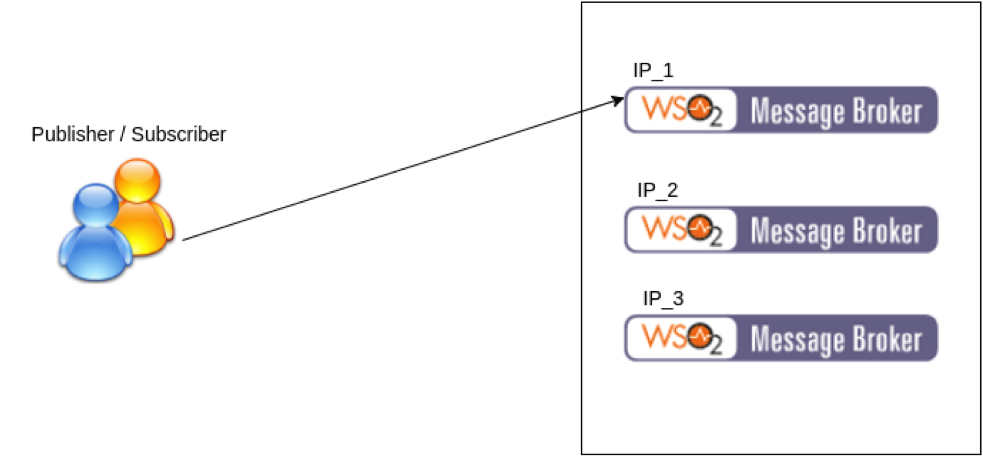
Figure 5
First, the developer needs to use WSO2 Andes client to achieve dynamic discovery
Based on the above-mentioned approach, a developer doesn't need to create the AMQP URL inside the JMS client program since it is automatically created by the andes client. The developer needs to set those properties when initializing the client.
The developer needx to define those variables first:
public static final String QPID_ICF = "org.wso2.andes.jndi.discovery.DynamicDiscoveryContext";
private static final String CF_NAME = "qpidConnectionfactory";
private static String CARBON_CLIENT_ID = "carbon";
private static String CARBON_VIRTUAL_HOST_NAME = "carbon";
private static String INITIAL_ADDRESSES = "IP_1,IP_2,IP_3";
private static String RETRIES = "0";
private static String CONNECTION_DELAY = "0";
private static String CYCLE_COUNT = "2";
private static String TRUSTSTORE_LOCATION = "{$MB_HOME} /repository/resources/security/wso2carbon.jks";
private final float TIME = 60;
private String USER_NAME = "admin";
private String PASSWORD = "admin";
private String TOPIC_NAME = "MYTopic";
private TopicConnection topicConnection;
private TopicSession topicSession;
Then define those properties which are needed to activate dynamic discovery:
Properties properties = new Properties();
properties.put(Context.INITIAL_CONTEXT_FACTORY, QPID_ICF);
properties.put(DiscoveryValues.AUTHENTICATION_CLIENT, USER_NAME +","+ PASSWORD);
properties.put(DiscoveryValues.CF_NAME_PREFIX + DiscoveryValues.CF_NAME, INITIAL_ADDRESSES);
properties.put(DiscoveryValues.CARBON_PROPERTIES, "" + CARBON_CLIENT_ID + "," + CARBON_VIRTUAL_HOST_NAME + "");
properties.put(DiscoveryValues.FAILOVER_PROPERTIES, "RETRIES=" + RETRIES + ",CONNECTION_DELAY=" +
CONNECTION_DELAY + ",CYCLE_COUNT=" + CYCLE_COUNT + "");
properties.put(DiscoveryValues.TRUSTSTORE, TRUSTSTORE_LOCATION);
Conclusion
This article focused on providing an introduction to dynamic discovery and connection level load balancing in distributed environment using WSO2 Message Broker.