Performance is a key constraint that limits business transaction processing volume, transaction responsiveness, and an application solution's ability to fulfill Service Level Agreements (SLAs). Both consumer- and partner-facing applications often process large transaction volumes with high throughput and low latency. Architecture and deployment topology play a significant part in the effectiveness of an application or service solution in terms of meeting business transaction processing goals. Technical capabilities often do not take center-stage, and business stakeholders and consumers who use WSO2's applications are only privy to the system running in production. To this end, we discuss three key areas; 1) Performance, 2) Deployment patterns, and 3) Capacity planning to provide an understanding of how objectives and requirements and IT capabilities are linked in a business environment.
We live in a world of consumer-driven business solutions where customers are not patient and are demanding; therefore, we need to constantly provide solutions that meet consumer needs and requirements. On the flip side, most IT solutions are business driven; business groups fund most IT projects, hence we need to provide solutions that meet their expectations; Therefore, performance becomes crucial. With evolution and globalization, today, we are not able to track the locations of those who join and use our applications. Carrying out comprehensive capacity planning is challenging in some instances because usage can fluctuate due to various reasons.
When analyzing performance, you would need to consider the following points:
Throughput – you would need to capture every transaction because these transactions carry a lot of business value and you cannot lose any transaction; therefore, when it comes to performance, throughput comes into the equation.
Latency – we have various SLAs and we need to meet the requirements outlined in these. For instance, if we say the roundtrip will be an x number of milliseconds or seconds, we would need to meet that criterion; hence, latency is an important aspect
Throttle – a single system cannot fulfill an entire business solution, so we run many systems; as a result, some of the systems might be slow. Therefore, we would need to throttle and transfer the transactions to suit every system's capabilities.
Quality of services – quality of service could vary:
If you consider a single process in terms of ability to scale, it can only handle a limited load due to software as well as hardware constraints that we currently face. Therefore, it’s not about the load a single unit can handle, but about how you can scale by adding more processing units into the architecture and running them. We have identified two ways of doing this:
When we add more nodes into run-time, those should be identical because every node should provide the same functionality. In addition, if there is any information that you need to share across your nodes, then those need to be synchronized as well. Furthermore, when you select an application layer or a middleware layer, it should support scalability to handle your high-performance needs.
Let's consider three products at WSO2, namely ESB, Message Broker and CEP, and analyze the following as illustrated in Table 1:
| LAB | Production | |
| Load | 100 X 1000 X 24h | 3.1B TPD |
| Throughput | 8000 TPS | 30,000 TPS |
| Latency | <1 ms | <3 ms |
Table 1: WSO2 ESB product performance
We have a flexible architecture where the transports come in an independent layer to the mediation layer as illustrated in Figures 1,2, and 3.
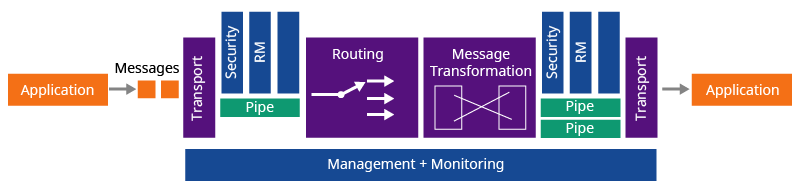
Figure 1: WSO2 ESB Architecture
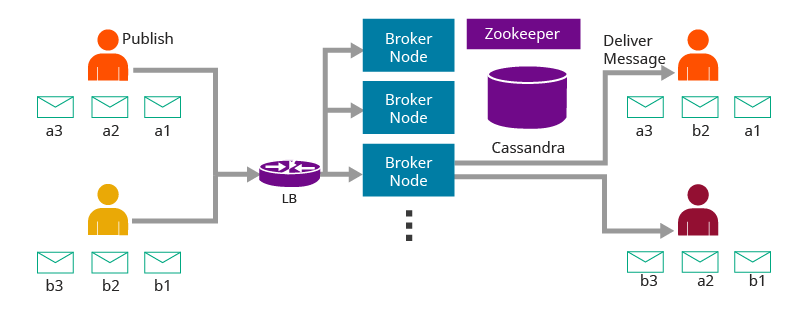
Figure 2: WSO2 Message Broker Architecture
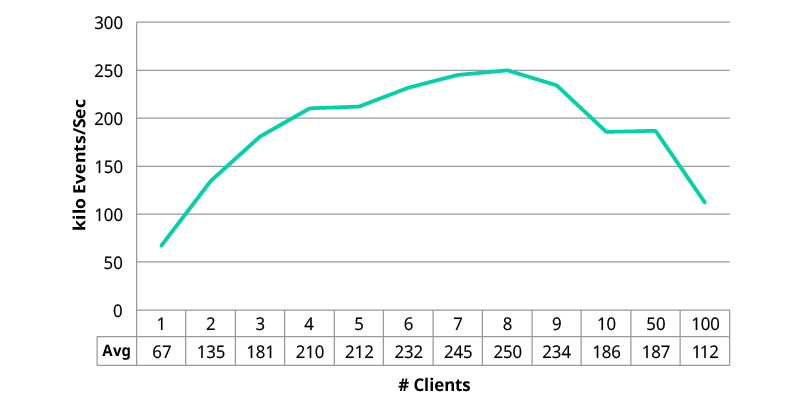
Figure 3: WSO2 CEP Performance Numbers
In the case of deployment flexibility and performance, if you have more deployment flexibility it will impact performance; therefore, if you have a distributed architecture, it can handle more throughput because some of the components can take on several transactions and some of the slow-moving parts can throttle or store and forward and pass the messages. It will add more latency between components and the network because components are distributed, and it will add some network latency to your performance as well.
Technical operations personnel generally do not favor adding more moving components because managing them is a challenge; however, if you have more moving components, you can scale each and every layer separately, and technical operations can utilize their infrastructure or hardware.
It is always important to pick a balanced approach by considering the required performance and the type of architecture that needs to be implemented. We have picked a few patterns (Figures 4, 5, and 6) for comparison purposes and to illustrate this point.
The first pattern introduces a cluster for high availability, so you can have an active and passive node and we then perform multi-casting to do the clustering; if you don’t enable multi-casting, we use well-known addressing where you can provide the host names and create a cluster. The disadvantage with this, however, is that although it will provide high availability, there will be a switching time between the active node and the passive node. In the second pattern, you can have any number of active instances and you can either have a static or elastic cluster by having any number of active instances. Hence, the elasticity demonstrates how you can dynamically scale.
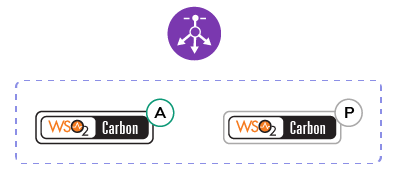
Figure 4: Pattern one – Cluster for High-availability
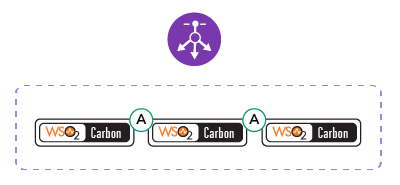
Figure 5: Pattern two – Cluster scalability
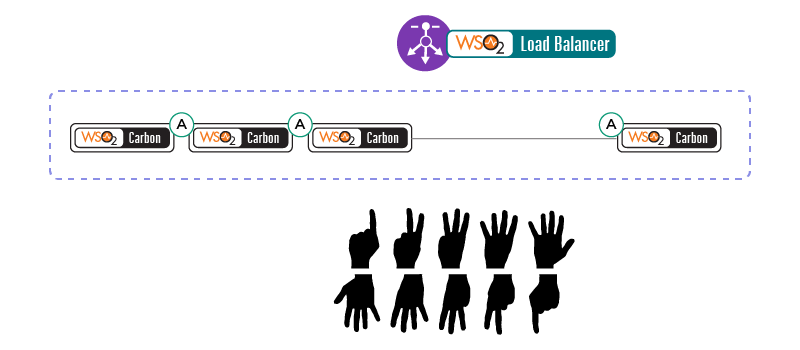
Figure 6: Pattern three – Cluster for Dynamic Scaling
In order to carry out capacity planning, we would require some form of data, and one way to gather data is via monitoring systems. There are various systems, and at WSO2, we have our own called the Business Activity Monitoring System. If you don’t have a system, another option is to review business and marketing statistics to compare present and projected information to determine the load that would need to be handled. The key information you would require is the maximum throughput or the transaction per second at peak, the type of latency (like system latency/overall latency you expect from your solution), and the size of the messages (which can be done by categorizing your messages).
We require work done per transaction to identify the number of CPU cycles required to fulfill one transaction. If you draw a sequence diagram, it would be easy to identify the work done per transaction and you can calculate the CPU cycles based on that.
You should note that what is required is the maximum value, and not the average value. You would need to know the TPS or TPM (per minute). Transactions per day are useless unless you have some store and process model in the architecture. Often, most messages in a day come within minutes. When there are no numbers to refer to, you could try to get a rough picture by figuring out if it’s 10s, 100s 1000s or 10000s and apply for a reasonable time window.
As illustrated in Figure 7, the first thing to do when carrying out a capacity planning exercise is to define the solution architecture. Assuming you have this, the next thing step is to gather data and fill the capacity planning matrix (at WSO2, we have a standard document we share if someone wants to carry out a capacity planning exercise). The next step is to identify the infrastructure and run-time to determine how you’re going to deploy this, e.g. are you using physical hardware and are you using a virtual environment, and the run-time components to identify the dependencies. Moreover, you need to identify infrastructure policies to ensure compliance in order to deploy the application. Non-functional requirements, such as high availability, security, and reliability, are equally important and need to be considered as well. To identify the instances, you need to refer to some existing performance numbers. WSO2 periodically publishes statistics, so you can refer to these and match it to a use-case that’s relevant to your requirements. With this, you can identify the instance count per each architecture layer, and we recommend running a performance test to verify and define the deployment architecture.
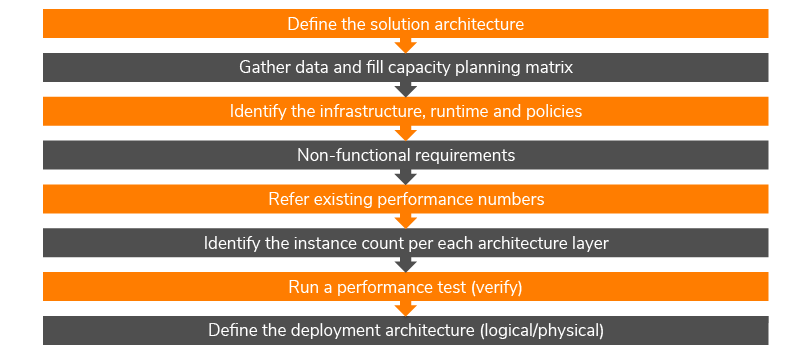
Figure 7: Capacity planning exercise
The following three levels of hardware specification are only a recommendation and are generic configurations, and will depend on your use case. It is subject to what you run and how you use the products.
Note: based on the I/O performance of M1-Medium instance recommend to run multiple instances in a Large instance.
In terms of capacity planning, we recommend the following best practices to better meet your requirements.
WSO2's middleware portfolio provides solutions that meet all requirements of consumers with regard to performance, particularly having high throughput and low latency. The solutions also provide the ability to scale, either dynamically or statically, and provide high-availability/reliability with zero downtime, as per responses from customers. WSO2 also provides deployment flexibility with many patterns where we can deploy on-premise as well as on Cloud and then hybrid mode as well because you can identify the pattern and deploy the solution given the flexibility we provide in the architecture. Hence, we could conclude that our architecture is built on a highperformance and scalable middleware platform; essentially, we deliver highly scalable and available solutions. For further guidance on how to build your deployment architecture by identifying the correct deployment patterns and reference architecture or further information about our solutions you could contact us by visiting https://wso2.com/contact
For more details about our solutions or to discuss a specific requirement contact us.