Streaming ETL With WSO2 Streaming Integrator

- Ramindu De Silva
- Senior Software Engineer - WSO2
The current state of ETL (Extract, Transform, Load) relies on streaming architecture. This is largely due to streaming data computation becoming common with real-time data and with the exponential growth of big data. In traditional ETL, transformation mainly focuses on data cleansing. Nowadays, data transformation has a different definition as it involves data cleansing, enriching, applying business rules, etc. This article takes a look at how WSO2 Streaming Integrator addresses emerging issues in ETL and addresses ad hoc architecture, the inability to facilitate new technologies, limitations of having data transformation capabilities only, and costly data visualization calculations. You can also refer to this article on ETL and how it changed over to time to learn more about the differences between traditional and modern ETL.
WSO2 Streaming Integrator’s Siddhi Sink, Source, and Store API for Extracting and Loading Functionality
When a system receives events from multiple sources and publishes to multiple targets, WSO2 Streaming Integrator can eliminate the ad hoc architecture via the Siddhi Sink, Source, Store APIs, and Mappers. Initially, the source mapper is responsible for standardizing the different schemas to adhere to one stream definition for the purpose of further processing. Finally, the Sink mappers are responsible for converting events to a structure that is required by the endpoints. APIs are used to build data pipelines in WSO2 Streaming Integrator and there are a handful of extensions such as Kafka, ActiveMQ, HTTP, etc., that can be used out-of-the-box. Even when a new technology emerges, it takes only a short amount of time to implement the API and plug it in.
Streaming Integrator’s Siddhi Core for Transforming
WSO2 Streaming Integrator is powered by Siddhi IO, which is an in-house stream processing engine. It is capable of building event-driven applications for use cases such as streaming analytics, data integration, notification management, and adaptive decision-making. Business logics can be executed with the help of Siddhi filters, windows, joins, sequences, and patterns. This falls into the transforming category in modern ETL. All these can be done in a stateful manner. If needed, you can also enable batch processing via windows.
Aggregations aggregate events incrementally for a specified set of time granularities and then allow you to access them in an interactive manner to produce reports, dashboards, and make decisions in real-time with millisecond accuracy. This eliminates the repetition of the same process when multiple data requests come in for the purpose of visualization.
Now that you have a basic idea of what WSO2 Streaming Integrator does, let’s provide a solution for a real-world problem. Let's say an organization’s production system dumps a file that contains information relating to a specific production batch. The file’s header contains the expected number of products of a certain batch that was predicted at the initial stages. The remaining file content will have the information of each and every product in the batch. The following is a sample file with the predicted and the actual batch information.

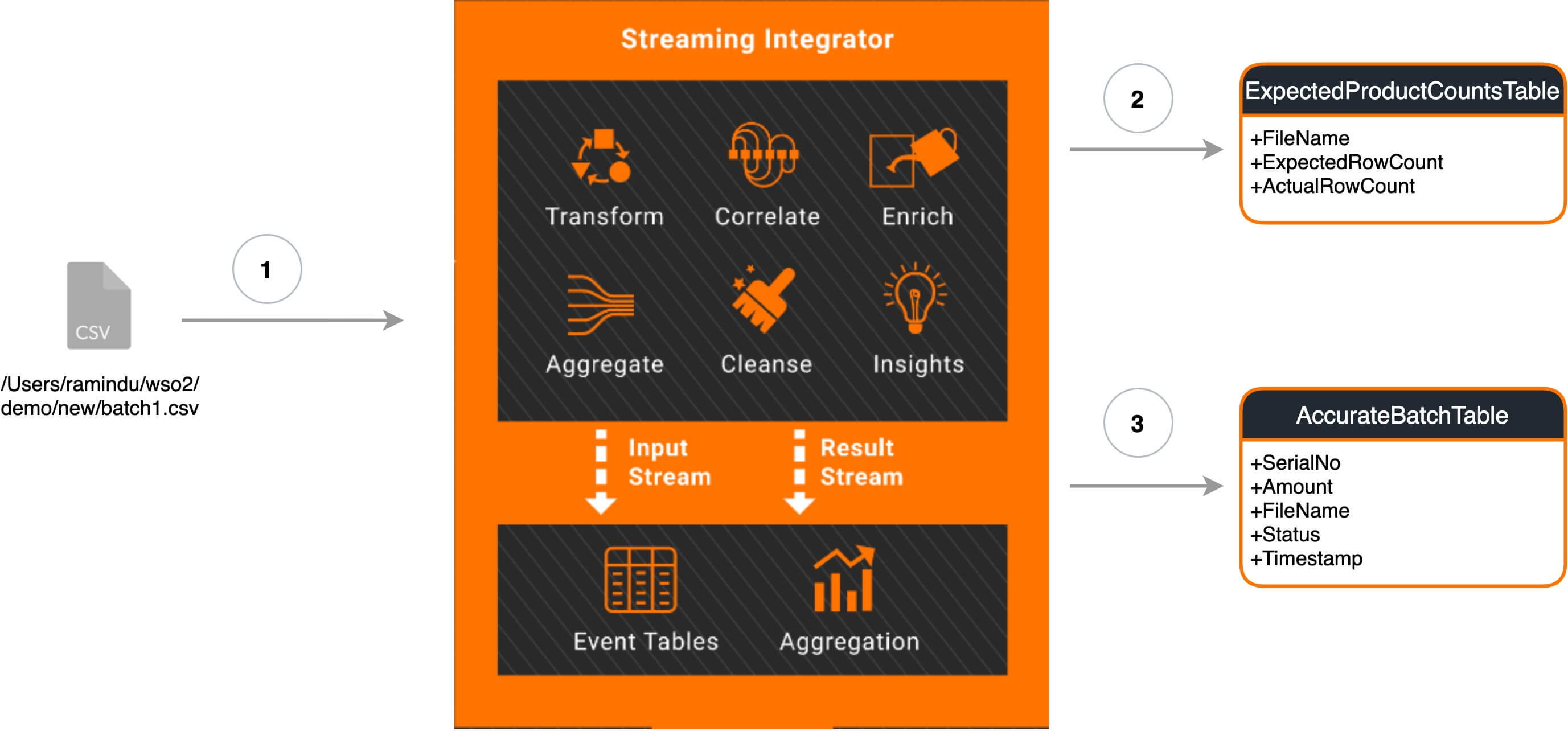
The production factory manager needs to get a report on the expected product prediction accuracy for future business purposes. The organization also needs accurate predictions in a separate database. The following diagram shows a high-level implementation of how WSO2 Streaming Integrator integrates a file with a database using Siddhi applications.
The following is the complete process diagram for the proposed solution.
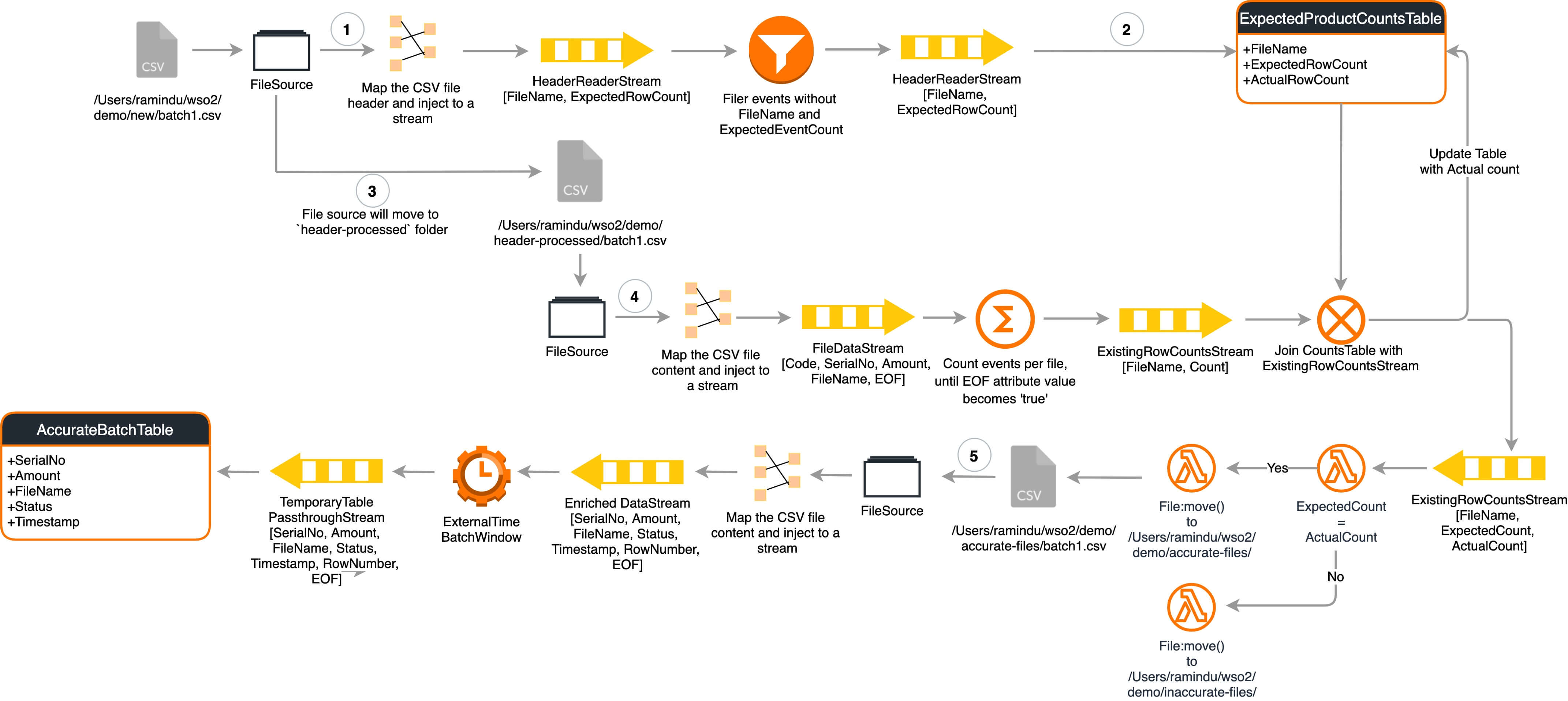
The solution is divided into the two parts that I've listed below. For the ease of understanding, I've also provided brief explanations of important queries.
- Analyze the files to identify headers (predicted product count) that match the content (actual product count) and move files to a given success or failure location.
- Listen to the directory that the success files have copied and stream the file data to the database.
Step 1: Analyzing Files to Identify Headers That Do Not Match the Content
Analyzing headers
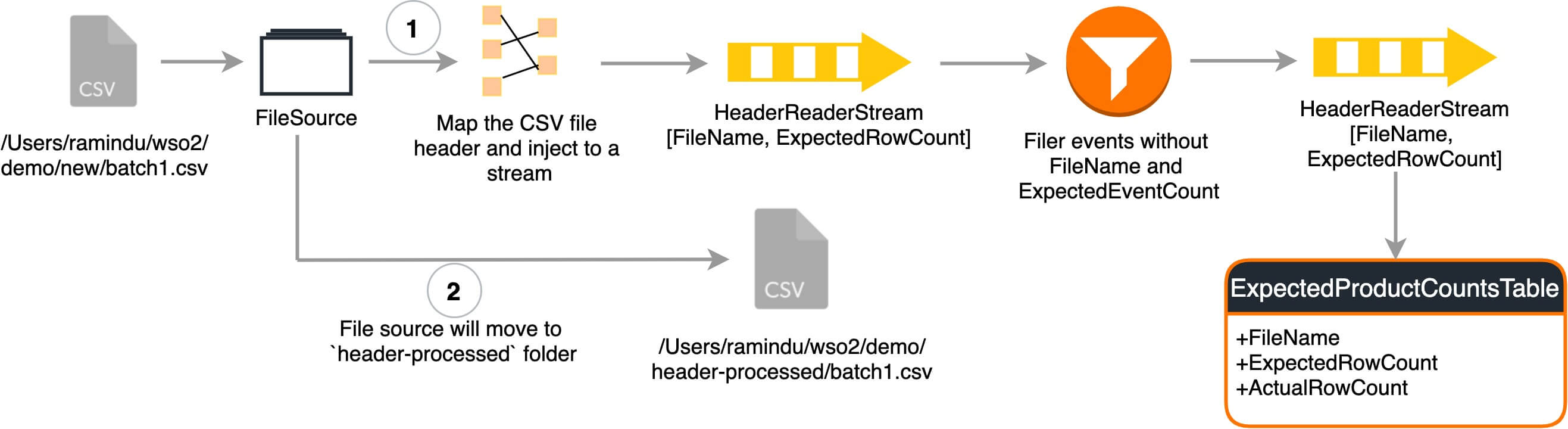
A file source reads the files in a given location. The source reads the file content in regex mode that adheres to the format of HDprod-itemName-2010-12-01-123456. After reading the content, the file name and the expected row count is sent to the HeaderReaderStream` and the read file is moved to the header-processed. folder.
from HeaderReaderStream[NOT(expectedRowCount is null) and NOT(fileName is null)] select * insert into ExpectedRowCountsStream;from ExpectedRowCountsStream select fileName, expectedRowCount, -1L as existingRowCount insert into ExpectedRowCountsTable;
The above queries validate the filename received via end of file attribute and the expected row count retrieved from the HDprod-[a-zA-z]*-[0-9][0-9][0-9][0-9]-[0-9][0-9]-[0-9][0-9]-([0-9]+) regex and insert the results to the ExpectedRowCountsTable.
Streaming file content and moving accurate files to a specific location to be read by the next Siddhi application

A file source reads files from the header-processed folder line by line without reading the header and passes the information to the FileReaderStream.
partition with (fileName of FileReaderStream)
begin
from FileReaderStream
select fileName, count() as rowCount, eof
insert into #ThisFileRowCounts;
The file processing is partitioned based on the file names. Row count calculation is done in parallel for separate files. The method aggregates the event count received from the FileReaderStream and when the eof (end of file) parameter becomes true, the count is sent to the ExistingRowCountsStream.
from ExistingRowCountsStream as S inner join ExpectedRowCountsTable as T on str:replaceFirst(S.fileName,
'header-processed', 'new') == T.fileName
select S.fileName as fromPath, T.expectedRowCount as expectedRowCount, S.existingRowCount as
existingRowCount
insert into FileInfoMatcherStream;
The ExistingRowCountsStream joins with ExpectedRowCountsTable on the condition where the file name is the same and enriches the FileInfoMatcherStream` with the file name, expected row count, and the existing row count. This stream later updates the ExpectedRowCountsTable.
Based on the values for the expectedRowCount and existingRowCount parameters, the read file is moved to accurate-files or inaccurate-files via the file: move() function.
Step 2: Streaming Accurate File Data to the Database

A file source listens to the files dumped to the accurate-files file location via the initial application and injects the file content to FileReaderStream after reading the file content line by line.
from DataStreamPassthrough#window.externalTimeBatch(timestamp, 5 sec, timestamp, 10 sec) select serialNo, amount, fileName, status, timestamp, rowNumber, eof insert into TemporaryTablePassthrough;from TemporaryTablePassthrough#window.batch() select serialNo, amount, fileName, status, timestamp insert into AccurateBatchTable;
The file events are batched before sending and then sent to the TemporaryTablePassthrough stream. The events are then added to the RDBMS table preserving the batch via the TemporaryTablePassthrough#window.batch() window. The RDBMS extension inserts events in a batch form that increases performance in database operations.
Prerequisites
- MySQL database
- A running instance of WSO2 Streaming Integrator Tooling server
- Click here for instructions on how to download and start WSO2 Streaming Integrator Tooling server.
- Download MySQL JDBC driver from here. Then copy the jar to the {ToolingServerHome} / lib directory.
- ETL_File_Analyzer.siddhi and ETL_File_Records_Copier.siddhi files
- Download and unzip demo.zip folder to your local machine
- The user with which you are logging into the WSO2 Streaming Integrator Tooling server must have read and write access for the file location
Executing the Sample and Viewing the Results
- You can either save the above ETL_File_Analyzer.siddhi and ETL_File_Records_Copier.siddhi files in the {ToolingServerHome}/wso2/server/deployment/workspace folder or import them by clicking File -> Import Sample.
- Replace /Users/wso2/ texts in both the Siddhi files with the path to the location where you unzipped demo.zip in your machine.
- Start ETL_File_Records_Copier.siddhi first and ETL_File_Analyzer.siddhi after that.
- Check the carbon console for the results. Furthermore the accurate batch product information will be available in the AccurateBatchTable in batchInformation Database.
Watch this video to learn more about how you can run the sample in WSO2 Streaming Integrator Editor.
On a separate note, WSO2 Streaming Integrator is able to analyze a file with 6,140,031 Lines (size: 124M), and copy the data to a database (AWS RDS instance with oracle-ee 12.1.0.2.v15) in 1.422 minutes (85373ms) using an m4.xlarge instance.
| Lines | 6,140,031 |
| Size | 124MB |
| Database | AWS RDS instance with oracle-ee 12.1.0.2.v15 |
| Duration | 1.422 minutes (85373ms) |
Summary
This article describes how you can use WSO2 Streaming Integrator to integrate a file with a database with unique business logic. The examples discussed in this article features integration done via a CSV file. WSO2 Streaming Integrator can integrate other sources such as Kafka, Http, ActiveMQ with modern data storage such as Amazon S3, Microsoft CosmosDB, Cassandra, etc. and vice versa with more complex business logic executing sequences and event patterns.
About Author
- Ramindu De Silva
- Senior Software Engineer
- WSO2