High Availability and Coordination
When you deploy several instances of the same FTP/SFTP integration, for example, one per pod in a Kubernetes cluster, every instance would normally connect to the same remote directory and pick up every file. That causes duplicate processing, race conditions, and inconsistent downstream state.
Turning on Coordination fixes this. One instance is elected as the active node and polls the server; the others stay as warm standbys and take over automatically if the active one goes down. You only need one extra thing, which is a shared database the nodes use to elect a leader and exchange heartbeats.
How it works
| Step | What happens |
|---|---|
| 1. Leader election | On startup, every node in the same coordinationGroup registers with the shared database. One node is elected active. |
| 2. Heartbeat | Every node in the group (active and standby) writes its own heartbeat row at the heartbeatFrequency interval. This advertises liveness so any node can be promoted when needed. |
| 3. Liveness check | Standby nodes periodically check the active node's heartbeat. If the heartbeat goes stale, the active node is considered dead. |
| 4. Failover | A standby is promoted to active and starts polling immediately without manual intervention. |
| 5. Polling behavior | Only the active node polls the FTP/SFTP server. Standby nodes skip polling entirely, consuming no FTP server resources. |
The pattern is active-passive: at most one node polls at a time. Per-file locking across multiple active pollers isn't supported.
Enabling coordination
- Visual Designer
- Ballerina Code
-
Open the listener by clicking its name under Listeners in the sidebar, or under Attached Listeners in the FTP Integration Configuration panel.
-
Scroll to the Coordination field and click Record to open the builder.
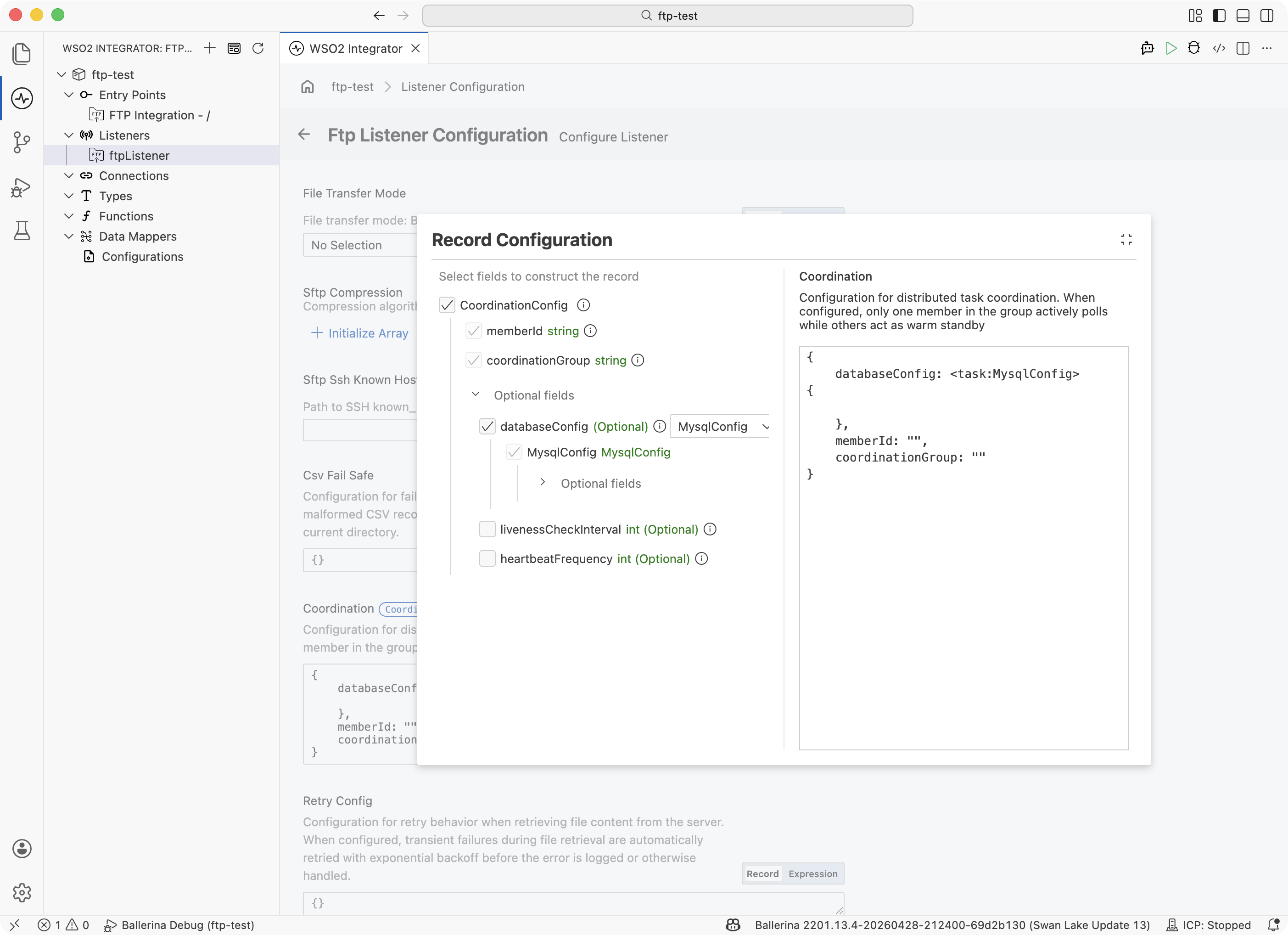
-
Fill in the three required fields:
Field What to enter Member ID A unique name for this instance of the integration. Every pod or instance must have a different value. Typically sourced from a configurableso each deployment can set its own.Coordination Group A shared name that all instances of the same listener use. Instances with matching group names coordinate; instances with different group names are independent. Database Config Connection details (host, port, user, password, database) for the shared MySQL or PostgreSQL database used to track leader election. -
Save the listener. Deploy each instance with a different Member ID.
Add a coordination record to the ftp:Listener configuration. Source memberId from a configurable so each deployment sets its own value; keep coordinationGroup identical across instances you want to coordinate.
import ballerina/ftp;
import ballerina/task;
// The driver import is required at runtime even though it isn't referenced
// directly. Use `ballerinax/postgresql.driver as _` for PostgreSQL.
import ballerinax/mysql.driver as _;
configurable string memberId = ?;
listener ftp:Listener ftpListener = new ({
host: "ftp.example.com",
port: 21,
auth: {credentials: {username: "user", password: "pass"}},
pollingInterval: 30,
coordination: {
databaseConfig: <task:MysqlConfig>{
host: "mysql.example.com",
user: "coordinator",
password: "secret",
database: "ftp_coordination"
},
memberId: memberId,
coordinationGroup: "incoming-files-group"
}
});
service on ftpListener {
remote function onFileText(string content, ftp:FileInfo fileInfo) returns error? {
// Only one instance in the cluster executes this handler per file.
}
}
ftp:CoordinationConfig fields:
| Field | Type | Default | Description |
|---|---|---|---|
databaseConfig | task:DatabaseConfig | — | Connection details for the coordination database. Accepts MysqlConfig or PostgresqlConfig. Required. |
memberId | string | — | Unique identifier for this node. Must be distinct across all nodes in the coordination group. Required. |
coordinationGroup | string | — | Name of the coordination group. All listeners with the same group coordinate together. Required. |
livenessCheckInterval | int | 30 | Seconds between heartbeat checks by standby nodes. |
heartbeatFrequency | int | 1 | Seconds between heartbeat writes by the active node. |
The runtime trusts the Member ID you provide. It does not check that the value is unique across your cluster. If two pods come up with the same Member ID in the same Coordination Group, both may become active, leading to duplicate processing.
Database schema
Create the coordination tables in your MySQL or PostgreSQL database before starting the first instance. The runtime does not create them for you. Both dialects are supported; use whichever your ops team already runs.
- MySQL
- PostgreSQL
CREATE TABLE token_holder (
group_id VARCHAR(128) NOT NULL PRIMARY KEY,
task_id VARCHAR(128) NOT NULL,
term BIGINT NOT NULL DEFAULT 1
);
CREATE TABLE health_check (
task_id VARCHAR(128) NOT NULL,
group_id VARCHAR(128) NOT NULL,
last_heartbeat DATETIME NOT NULL,
PRIMARY KEY (task_id, group_id)
);
CREATE TABLE token_holder (
group_id VARCHAR(128) NOT NULL PRIMARY KEY,
task_id VARCHAR(128) NOT NULL,
term BIGINT NOT NULL DEFAULT 1
);
CREATE TABLE health_check (
task_id VARCHAR(128) NOT NULL,
group_id VARCHAR(128) NOT NULL,
last_heartbeat TIMESTAMP NOT NULL,
PRIMARY KEY (task_id, group_id)
);
Every node in a coordinationGroup shares the same two tables. The runtime writes heartbeats to health_check, elects a leader by upserting token_holder, and compares last_heartbeat against the database's own CURRENT_TIMESTAMP for liveness. You don't need to pre-seed any rows, creating the tables is enough.
Database availability
Coordination depends on the shared database being reachable. If the database goes down:
- The active node stops polling, its heartbeat writes fail, and file dispatch halts until the database comes back. Files that arrive on the FTP/SFTP server during the outage are processed only after the database is restored and polling resumes.
- Standby nodes also cannot take over until the database is reachable again. On recovery, a standby promotes itself within one liveness-check interval and begins polling.
Treat the coordination database as critical infrastructure on the data path: plan replicas, backups, and failover to the same standard as your FTP/SFTP source.
The coordination database sits on the file-processing data path: its availability directly determines whether files are picked up. Add it to your infrastructure monitoring (uptime checks, query latency, connection counts) alongside the FTP/SFTP source itself, so your operators are alerted by the database, not by files piling up at the source.
What's next
- FTP / SFTP — service, listener, and file-handler reference
- Scaling and high availability — deployment-level scaling and HA strategies