Why Prompt-Based Guardrails Are Not Enough: Enforcing AI Safety Beyond the Model

- Vihanga Liyanage
- Associate Lead Sales Engineer, WSO2
The illusion of control in AI systems
As AI applications evolve from simple chatbots to autonomous agents, many teams rely heavily on prompt engineering to control behavior. Instructions such as “do not expose sensitive data” or “avoid destructive actions” are embedded directly into system prompts, creating a perception that the system is governed and safe.
This approach is appealing because it is simple and fast to implement. It gives the impression that the model is aware of constraints and will follow them. In early-stage prototypes, this often appears to work, reinforcing confidence in prompt-based guardrails.
The misconception: Instructions equal control
A common assumption in AI system design is that if a model is explicitly instructed, it will comply. In reality, prompt-based guardrails are advisory rather than enforceable. Models interpret instructions probabilistically, where behavior varies based on phrasing, surrounding context, and the underlying provider. Research has also shown that even when agents are provided with structured plans and explicit instructions, there is no guarantee they will follow them [1]. As a result, prompts may influence behavior, but they cannot guarantee policy enforcement or prevent unsafe outcomes.
When instructions fail in practice
The following are a very few real-world incidents from a large list that highlight the limitations of relying solely on prompt-based guardrails.
- An AI coding agent deleted a production database after making a destructive API call despite being instructed not to perform such actions [2].
- Samsung engineers exposed internal source code and confidential data by sharing it with ChatGPT despite existing warnings and policies around sensitive information handling [3].
- A Chevrolet dealership chatbot was manipulated through prompt injection into agreeing to sell a $76,000 vehicle for $1 while treating its responses as legally binding [4].
- Researchers extracted and bypassed Microsoft Bing Chat system instructions using prompt injection techniques, exposing internal prompts and safeguards [5].
Across these examples, the pattern is consistent: instructions were present, but the models still violated them. This reinforces a critical point.
From guidance to enforcement: The architectural shift
To build reliable AI systems, guardrails must move from the LLM layer to an enforcement layer. This mirrors a well-established pattern in API architectures. Just as API gateways provide centralized control over API traffic for authentication, rate limiting, and policy enforcement, AI systems require a similar control point.
In this architecture:
- The LLM acts as a processing engine that generates responses
- An external layer acts as an enforcement engine that validates and controls behavior
This enforcement layer is responsible for:
- Inspecting both inputs and outputs
- Enforcing schemas and response structures
- Detecting and masking sensitive data
- Applying consistent policies across all requests
- Controlling actions before they are executed
By separating generation from enforcement, organizations can ensure that policies are applied consistently, regardless of how the model behaves. Some enforcement checks are deterministic, such as regex validation, schemas, and allow/deny lists, while others remain probabilistic, such as PII or prompt-injection detection. The key architectural shift is not making every check deterministic, but ensuring enforcement is centralized, consistent, and applied uniformly to every request.
How WSO2 enables enforced AI guardrails
WSO2 API Platform, with its AI Gateway capability, introduces a centralized enforcement layer between applications and LLMs. This enables organizations to:
- Inspect and control inputs before they reach the model
- Prevent sensitive data exposure
- Apply validation and filtering
- Validate and enforce outputs before they are returned
- Ensure responses meet policy and format requirements
- Block or transform unsafe or non-compliant outputs
- Apply consistent guardrails across models
- Works independently of the underlying LLM provider
- Eliminates variability in how policies are enforced across providers
- Control actions triggered by AI systems
- Intercept API calls initiated by agents
- Enforce authorization, approval flows, and restrictions
- Centralize governance and observability
- Monitor AI traffic
- Apply policies uniformly across all AI interactions
This approach shifts AI safety from best-effort guidance to guaranteed enforcement. Instead of asking the model to follow rules, the system ensures that rules are followed, regardless of model behavior.
A concrete example
Consider a customer service agent asked to summarize a customer's account. The agent calls an internal customer-record tool, which returns a payload containing the customer's SSN. Before that payload reaches the LLM, the AI gateway's PII policy detects the SSN and masks it in the request body, and logs the event for compliance review. The LLM receives a sanitized version of the record and never sees the SSN at all. Any summary it produces is safe by construction, regardless of what the model does with the rest of the context.
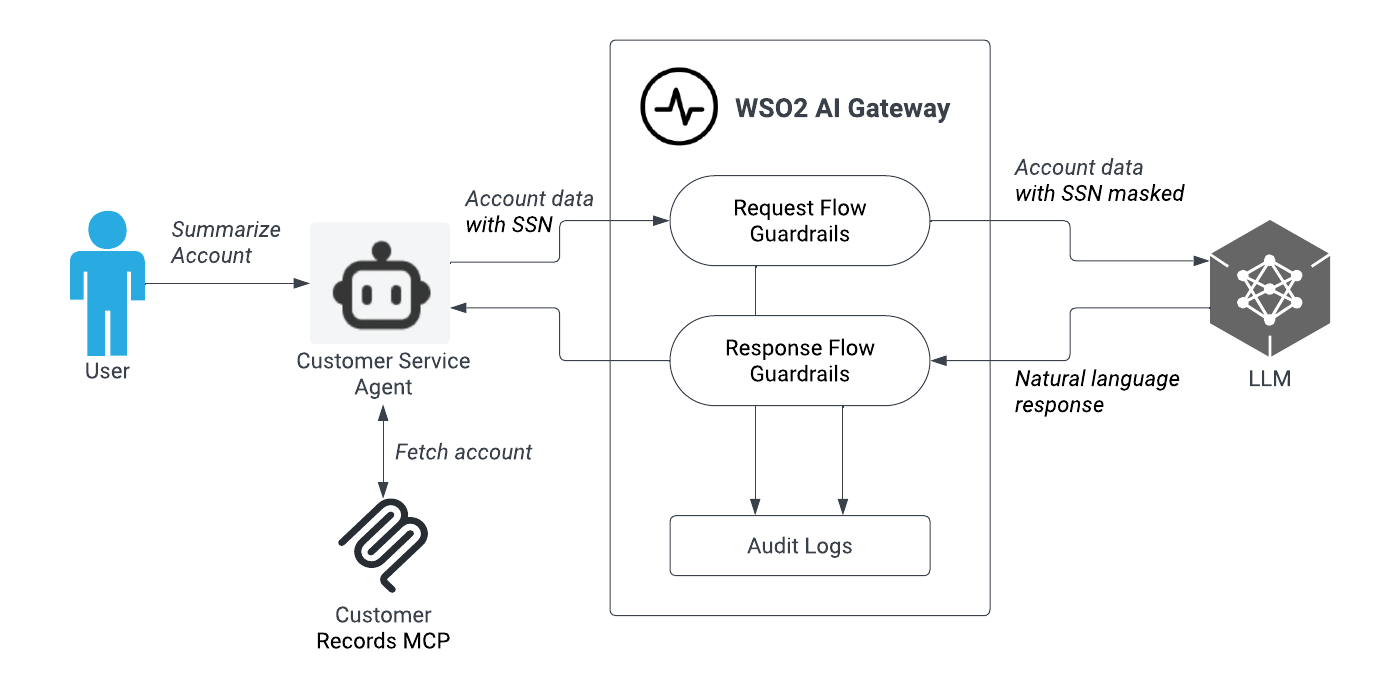
Figure 1: Example scenario: How AI Gateway intercepts tool payloads
Key takeaway
Prompt-based guardrails attempt to influence behavior inside the model. Effective AI governance requires enforcement outside of it, a deterministic control layer that applies policies regardless of how the model behaves. That's the distinction between AI systems that might be safe and AI systems that are governed.
References
[1] - Paper: Evaluating Plan Compliance in Autonomous Programming Agents (https://arxiv.org/abs/2604.12147)
[2] - https://www.theguardian.com/technology/2026/apr/29/claude-ai-deletes-firm-database
[3] - https://incidentdatabase.ai/cite/768
[4] - https://incidentdatabase.ai/cite/622
[5] - https://incidentdatabase.ai/cite/473