Understanding Complex Event Processing (CEP) Operators with WSO2 CEP (Siddhi)

- Srinath Perera
- Chief Architect - WSO2 Inc.
CEP model have many sensors. A sensor can be a real sensor (e.g. temperature sensor), some agent, or a system that support instrumentation. Sensor sends events to CEP and each event has several name value properties.
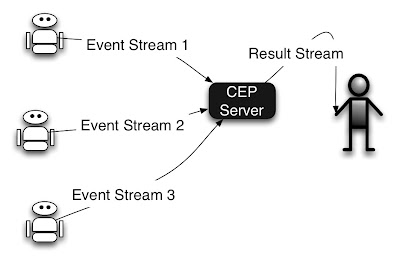
We call events coming from the same sensor as a “stream” and give it a name. When an interesting event occurs, the sensor sends that event to the stream.
To use a stream, you need to first define them.
define stream PizzaOrders (id string, price float, ts long, custid string)
CEP listens to one or more streams, and we can write queries telling the CEP to look for certain conditions. For writing queries, you can use following constructs.
- Filters
- Windows
- Joins
- Patterns and Sequences
- Event tables
- Partitions
Let us see what we can do with each construct.
Filter
Filter checks a condition about property in an event. It can be a =, >, etc., and you can create complex queries by combing multiple conditions via and, or, not etc.
Following query detect pizza orders that are small and placed too far from the store.
select from PizzaOrders[price = 20 and distance>1km]
insert into NBNOrders id, price, distance
Windows
An event stream can have an infinite number of events. Windows are a way to select a subset events for further processing. You can select events in many ways: events came in a time period, last N events etc.
Output from a window is set of events. You can use it for further processing (e.g. joining event streams) or calculate aggregate function like sum and average.
We can either get output to be triggered when all events are collected or whenever a new event is added. We call the first type batch windows and second sliding windows.
For example, window can collect all pizza orders placed in the last hour and emit the average value of the order once every hour.
from PizzaOrders#window.time( 1h ) into HourlyOrderStats avg(price) as avgPrice
Joins
Join operator join two event streams. Idea is to match event coming from two streams and create a new event stream.
For example, you can use join operator to join PizzaDelivery stream and PizzaOrder stream and calculate the time took to deliver each order.
from PizzaOrder#window.time(1h) as o join PizzaDelivery as d on o.id == d.id insert into DeliveryTime o.id as id, d.ts-0.ts as ts
At least one side of the join must have a window. For example, in above example, we can have a one hour window for PizzaOrder (because delivery always happens after the order) where join will store the events coming in PizzaOrder for one hour and match them against delivery events. If you have two windows, join will store events at each stream and match them against events coming to the other stream.
Patterns and sequences let us match conditions that happen over time.
For example, we can use patterns to identify returning customers using following query. Here -> denotes followed by relationship.
from every a1 = PizzaOder
-> a2 = PizzaOder[custid=a1.custid]
insert into ReturningCustomers
a1.custid as custid a2.ts as ts Patterns match even when there are other events in between two matching conditions. Sequences are similar, but provided event sequence must exactly match the events that happened. For example, following is the same query implemented using sequences. Note here second line is to ignore any not matching events.
from every a1 = PizzaOder,
PizzaOder[custid!=a1.custid]*,
a2 = PizzaOder[custid=a1.custid]
insert into ReturningCustomers
a1.custid as custid a2.ts as ts Here instead of -> relationship we use regular expression like notation to define sequence of conditions.
Partitions (available in upcoming 3.0 release)
Siddhi evaluates a query matching all the events in event streams used by that query. Partitions let us partition events into several groups based on some condition before evaluating queries.
For example, let say we need to find the time spent until pizza left shop and until it is delivered. We can first partition pizza orders by orderID and then evaluate the query. It simplifies the query by great extent.
define partition oderParition by PizzaOder.id, PizzaDone.oid, PizzaDelivered.oid select from PizzaOder as o ->PizzaDone as p -> PizzaDelivered as d insert into OrderTimes (p.ts-o.ts) as time2Preprae, (d.ts-p.ts) as time2Delivery partition by oderParition
We do this for several reasons.
- Evaluating events separately within several partitions might be faster than matching them all together. In the later case, we match events only within the partition.
- Sometime it makes queries easier to design. For example, in the above query, partitioning let us write a query without worrying about other orders that are overlapped with the same order.
- Partitions let CEP runtime to distribute evaluation to multiple machines, and this can helps when scaling queries.
Event Tables (available in upcoming 3.0 release)
Event tables let you remember some events and use them later. You can define a table just like a stream.
define table LatePizzaOrdersTable (ordered string, ts long, price float);
Then you can add events to it, delete events from it, and join those events in the table against incoming events.
For example, lets say we need to store all late deliveries and if late delivery happend to the same customer twice we want to give them free pizza.
from LatePizzaDeliveries insert into LatePizzaOrdersTable;
Then we can join events from event table with incoming events as follows.
from LatePizzaDeliveries as l join LatePizzaOrdersTable as t
on l.custid=t.custid AND l.ts!=t.ts
insert into FreePizzaOrdersYou can also do the same using an event stream. However, event tables can be written to the disk and very useful for the long running usecases. For example, if we do the above using an event stream stored values will be lost when we restart the server. However, values in event tables will be preserved in a disk.
About Author
- Srinath Perera
- Chief Architect
- WSO2 Inc.