ScheduleMe: What a Multi-Agent Calendar Assistant Reveals About Building Reliable AI Applications

- Srinath Perera
- Chief Architect , WSO2 Inc.
Large language models have made AI accessible to more developers and unlocked many use cases that were previously infeasible. However, handling a complex use case (e.g., calendar management or travel planning) and achieving results comparable to human performance requires sophisticated reasoning, design, and agent cooperation.
In “ScheduleMe: Multi-Agent Calendar Assistant”, published at the 39th Pacific Asia Conference on Language, Information and Computation (PACLIC), we present an approach that shows how structured reasoning and agent cooperation can increase the usability and flexibility of AI agents. We use a calendar assistant as a focused use case, built to leverage large language models (LLMs) within a multi-agent system to perform natural language calendar operations.
How ScheduleMe works
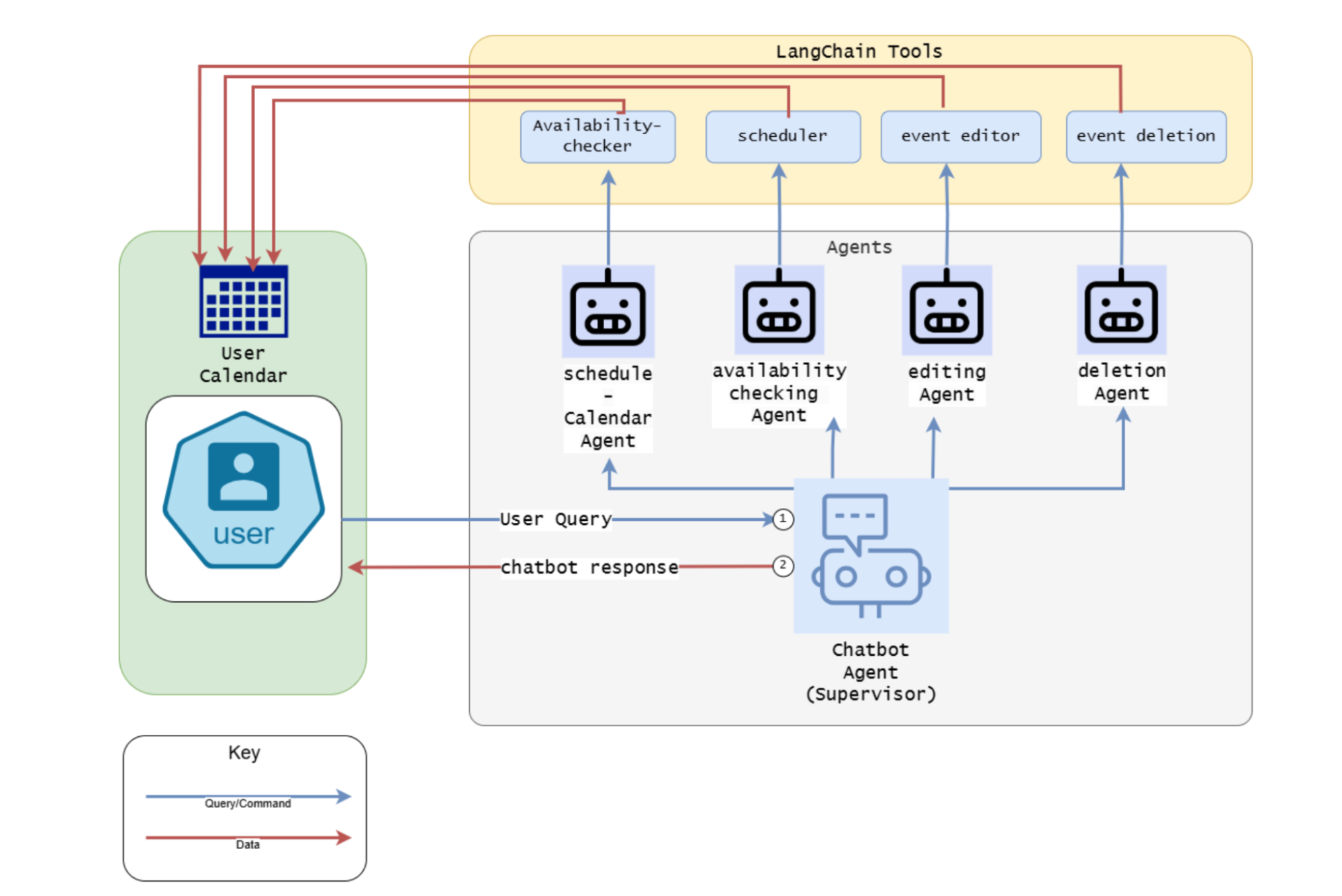
Figure 1: ScheduleMe architecture
As shown in Figure 1, a supervisor agent receives the user query, extracts the intent, and delegates subtasks to one of the specialized functional agents: the scheduling agent, the availability-checking agent, the event-editing agent, or the event-deletion agent. Each agent used the ReAct pattern; they use tools that abstract out the Google Calendar APIs. For reasoning, the system used OpenAI’s GPT-4o mini.
To support scale, ScheduleMe can run multiple supervisor instances that operate in parallel. A load balancer routes each session request to the least loaded supervisor, ensuring session affinity and enabling automatic reassignment in the event of failure. This design eliminates the single point of failure and significantly improves throughput under high concurrency.
Testing across languages and tasks
The team conducted two experiments to evaluate the system.
The first experiment tested the assistant using 120 queries, with four task types: scheduling, availability checking, editing, and deletion, 5 queries per task, for six languages. The results are given below.
| Language | Schedule | Avail. | Edit | Delete | Total | Success% |
| English (En) | 5/5 | 5/5 | 5/5 | 5/5 | 20/20 | 100% |
| Franch (Fr) | 5/5 | 5/5 | 4/5 | 4/5 | 18/20 | 90% |
| German (De) | 5/5 | 5/5 | 3/5 | 4/5 | 17/20 | 85% |
| Tamil (Ta) | 5/5 | 4/5 | 3/5 | 3/5 | 15/20 | 75% |
| Sinhala (Si) | 5/5 | 5/5 | 2/5 | 2/5 | 14/20 | 70% |
| Chinese (Zh) | 4/5 | 3/5 | 3/5 | 3/5 | 13/20 | 65% |
The calendar assistant handled tasks across all six languages. Editing and deletion were the most variable, with performance dropping in lower-resource languages (a pattern worth noting for teams building multilingual AI systems).
The second experiment was a user study with 20 users who are frequent digital calendar users. Each participant completed 5 -7 calendar operations, including a mix of simple, complex, and multilingual requests. Participants recorded task success and error rates as objective metrics. After completing the tasks, they completed a System Usability Scale (SUS) questionnaire and rated trust and satisfaction on a five-point Likert scale. The system received a 92.0 Task Success Rate (%), with a SUS Score (0–100) of 82.5, a Trust Rating of (1–5) 4.3, and a Satisfaction Rating (1–5) of 4.6.
Both experiments suggest that the proposed system shows strong results with 82% SUS score (68% average for web [2]) that can be described as "Excellent" as per the Adjective Rating Scale [2] and 92% tasks success rate (industry average 78% [2]). These results suggest the system is well within the range that real users find reliable and usable.
You can find more details from the original paper at https://arxiv.org/pdf/2509.25693.
Acknowledgments
This work is the result of a collaborative project between the Department of Computer Science and Engineering at the University of Moratuwa. The project team consisted of Oshadha Wijerathne, Amandi Nimasha, Dushan Fernando, Nisansa de Silva, and Srinath Perera.
1. What Is A Good Task-Completion Rate? https://measuringu.com/task-completion/
2. Determining What Individual SUS Scores Mean: Adding an Adjective Rating Scale, https://uxpajournal.org/wp-content/uploads/sites/7/pdf/JUS_Bangor_May2009.pdf