What is Semantic Caching?

- Matt Tanner
- Senior Director, Product Marketing - API Platform, WSO2

When we think of a typical API, part of a production-ready setup generally includes a cache. This cache allows for similar requests to be served without having to do the entire roundtrip. But when it comes to AI applications powered by large language models, traditional caching falls short. This is because queries to an AI endpoint may look different in terms of how things are worded or phrased but actually mean the same thing semantically. That's where semantic caching comes in: a technique that's become essential for running cost-effective and performant AI applications in production.
Introduction to semantic caching
Semantic caching is a technique used to improve the efficiency of large language models (LLMs) by storing frequently accessed data and reducing the number of cache misses (scenarios where the incoming query doesn't have a sufficiently similar match in the cache, so the system has to call the LLM to get a fresh response). Unlike traditional caching methods that require exact string matches, semantic caching uses vector similarity search to retrieve cached responses based on semantic meaning.
For example, consider these three user queries:
- "What's the capital of France?"
- "Tell me the capital city of France"
- "Which city is the capital of France?"
To a traditional cache, these are three completely different requests. This means that each one would be sent to your LLM provider, consuming tokens (which is where the cost comes into play) and time. But when looked at semantically, they're identical queries asking for the same information. Semantic caching solves this by understanding meaning, not just matching text in a request body or in query parameters as traditional caching would.
The benefits of implementing semantic caching include significantly reducing compute costs and improved response times in generative AI applications. A well-designed semantic cache system can provide accurate responses to user queries by retrieving relevant information from cached data, storing the semantic meaning of user queries and returning cached responses that match the query intent.
Understanding large language models (LLMs)
Large language models are AI systems trained on vast amounts of text data to understand and generate human-like responses. When you send a query to an LLM through an API, the model processes your input and generates a response based on its training. However, each API call to an LLM comes with costs—both in terms of actual dollars (charged per token) and time (latency for generating responses).
For production AI applications, these costs add up quickly. If your application serves thousands of similar queries daily, you're essentially paying for the same computation repeatedly. This is where semantic caching becomes not just an optimization, but a necessity for sustainable AI operations. By understanding how LLMs work and their associated costs, you can better appreciate why semantic caching has become a critical component of modern AI gateway architectures.
How semantic caching works
Digging a bit deeper, let's look at the inner workings of semantic caching and the technical details of how it works. Semantic caching uses a vector database to store cached responses and a vector search algorithm to retrieve relevant information. The process works fundamentally differently than traditional caching.
With traditional caching, it works like so:
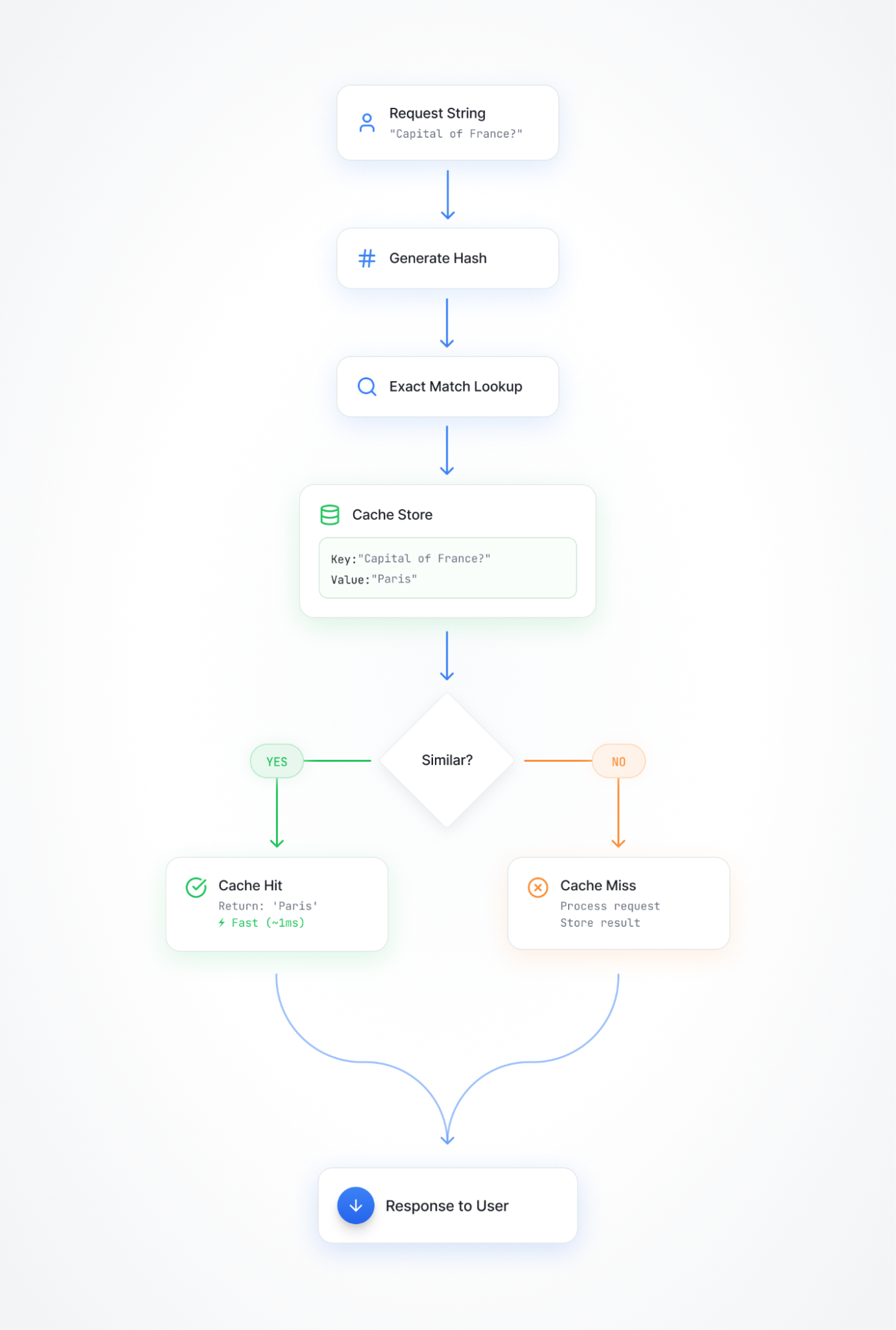
Semantic caching is quite different, and follows a pattern more like this:
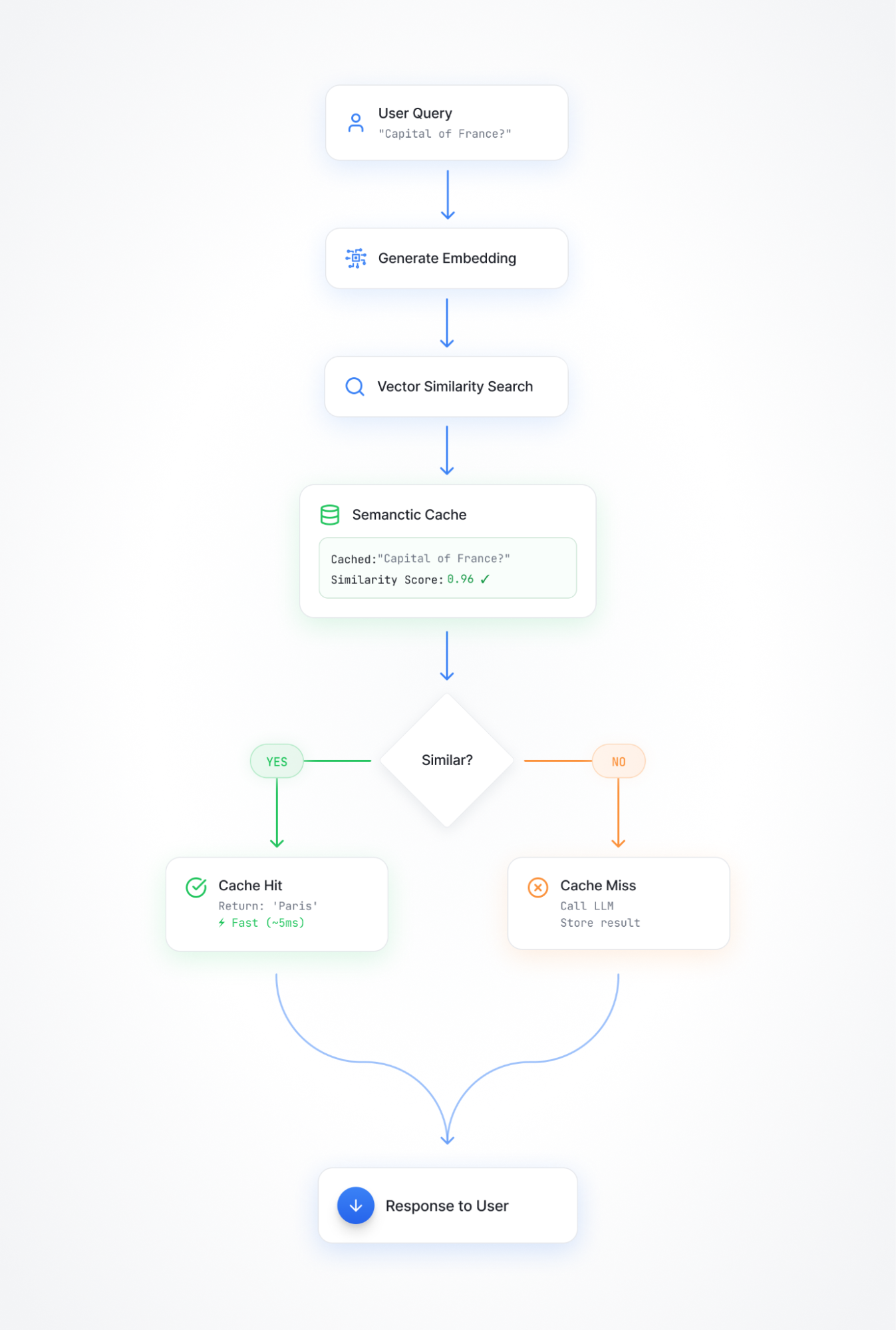
The cache stores frequently accessed data and their corresponding semantic meanings, allowing for efficient retrieval of relevant responses. Here's how the process flows:
- User submits a query to your AI application
- Generate a vector embedding of that query using an embedding model
- Search your vector database (vector similarity search) for cached responses with similar embeddings
- Calculate similarity scores between the query embedding and cached entry embeddings
- Return the cached response with the highest similarity score if it exceeds your configured threshold, reducing the need for the LLM to process the query
The system returns the cached response with the highest similarity score above the threshold, completely bypassing the LLM call. This doesn't mean that traditional caching can't also be used, both types of caching can sometimes be used in conjunction with each other to provide a hybrid approach to data retrieval.
Measuring efficiency
A good caching strategy should be efficient in order to be valuable. Measuring the efficiency of semantic caching is critical to ensuring that the system is performing optimally. With traditional caching you can usually judge cache efficiency by measuring cache hits vs. misses. With semantic caching, tracking efficiency is a bit more nuanced.
It's not to say that you shouldn't also use metrics such as cache hit rates and response times, as they can still help to evaluate the efficiency of the system. However, on top of these you also need to track:
- Similarity score distributions: Are most cache hits near your threshold, or well above it?
- False positive rate: How often does semantic caching return a cached response that isn't actually appropriate?
- Cost savings: What's your actual reduction in LLM API costs?
- Latency improvements: How much faster are cached responses compared to LLM calls?
The use of semantic similarity thresholds and vector similarity search can help to ensure that the cached responses are relevant and accurate. The efficiency of semantic caching can be improved by optimizing the cache size, similarity thresholds, embedding model, and vector search algorithm.
As the system processes more requests and responses, measuring efficiency is ongoing and requires continuous monitoring and evaluation. As your application usage patterns change, you may need to adjust thresholds, change embedding models, or modify cache invalidation policies.
Spotting semantically similar queries
Depending on the embedding model, similarity threshold, and other configuration options within the semantic cache setup, you'll potentially get different determinations for whether a query is semantically similar. Getting this dialed in is critical to finding and returning cached responses that are relevant and accurate. However, there's an art to getting this right. Set your similarity threshold too high, and you'll only match near-identical phrasings, defeating the purpose. Set it too low, and you'll return cached responses for queries that are only tangentially related, which will likely frustrate users with irrelevant answers.
Semantic similarity vs. exact match
Semantic similarity is a measure of how similar two pieces of text are in terms of their meaning, not their characters or words. This is fundamentally different from exact match caching.
Exact match caching methods require an exact match between the query and the cached response, whereas semantic caching uses vector similarity search to retrieve relevant responses. Exact matching works well for deterministic APIs where GET /users/123 is always the same request with the same response. But LLM applications break this model.
Semantic caching can provide more relevant responses than traditional caching methods by retrieving cached information that is contextually relevant to the user's query. The use of semantic similarity thresholds can help to ensure that the cached responses are relevant and accurate.
The math behind this involves vector embeddings, which are numerical representations of text in high-dimensional space. Text with similar meanings produces vectors that are close together in this space, measured using techniques like cosine similarity. When two query embeddings have a cosine similarity of 0.95 or higher, they likely mean the same thing, even if the exact words differ.
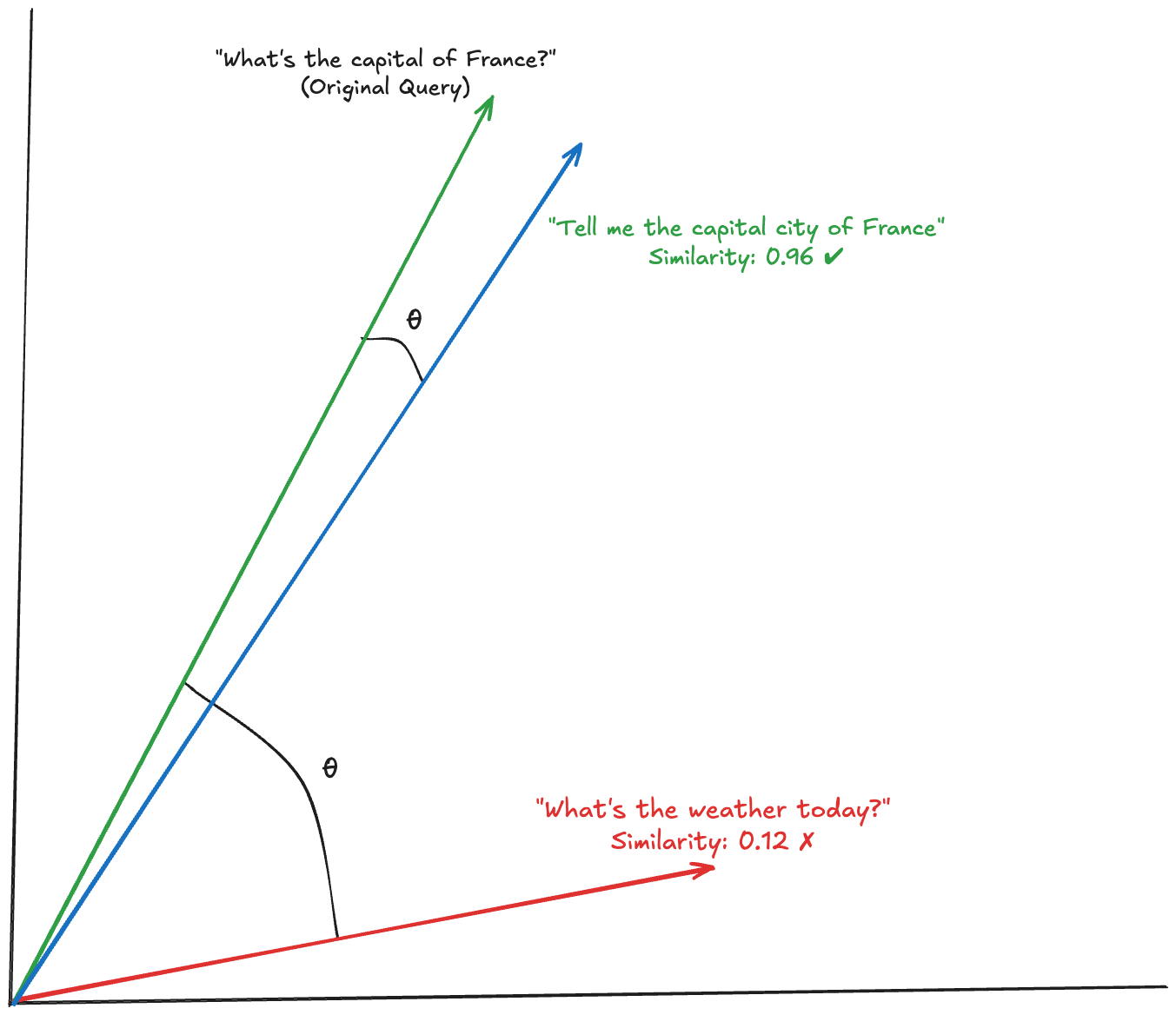
Back to our example, let's imagine that someone queries "What is the capital of France?". This query is then compared against other responses in the vector database, allowing the response with the closest similarity score to be returned (as long as it meets the similarity score threshold).
Semantic caching can be used to improve the efficiency of question answering systems and other applications that rely on LLMs. It's particularly effective for use cases where users ask similar questions repeatedly, such as FAQ systems, customer support, and documentation search.
Implementing semantic caching
To get semantic caching working, there are a few moving parts that are required. At first glance, the requirements seem straightforward:
- A vector database (Zilliz, Pinecone, Weaviate, Qdrant, etc.)
- An embedding model (OpenAI's text-embedding-3, Cohere, etc.)
- Similarity threshold logic
- Cache invalidation rules
You could strap all of this stuff together and roll-your-own solution, but as you start building, complexity emerges quickly. A well-designed semantic cache system should be able to handle a high volume of user queries and provide relevant responses quickly. However, building this at scale reveals several implementation challenges:
- Which embedding model? Different models produce different vector spaces. Do you use the same provider as your LLM? A dedicated embedding service? How do you handle model updates without invalidating your entire cache?
- Optimal similarity threshold: Set it too high (0.95+) and you'll get mostly cache misses. Set it too low (0.70) and you'll return irrelevant cached responses. The optimal threshold varies by use case and requires extensive testing.
- Cache invalidation: When your underlying data changes, how do you identify which cached responses are now stale? With traditional caching, you invalidate by key. With semantic caching, related queries might be cached under different vectors.
- Multi-turn conversations: Caching individual messages is one thing. Caching conversation context is significantly more complex, as the same question might have different answers depending on what was discussed previously.
Because of these challenges, using semantic caching that is available through an AI gateway is particularly valuable and makes implementation much easier.
Implementing semantic caching with WSO2's AI Gateway
Rather than building and maintaining this infrastructure yourself, WSO2's AI Gateway provides semantic caching as a managed capability within your API management layer.
WSO2's AI Gateway offers semantic caching as part of its comprehensive AI API management platform. The implementation handles the complexity of vector embeddings, similarity matching, and cache management behind a policy-based configuration interface.
Prerequisites
Before configuring semantic caching, you'll need to set up two components in your deployment.toml file (more specifics here):
- Embedding Provider: Choose from Mistral, Azure OpenAI, or OpenAI
- Vector Database: Configure Zilliz or Milvus for storing cached embeddings
These configurations define which embedding model generates the vector representations and where those vectors are stored for similarity search.
Configuring semantic caching
Setting up semantic caching in WSO2's AI Gateway follows a policy-based approach that requires configuration in both request and response flows:
- Navigate to Policy Configuration: In the WSO2 API Publisher Portal, select your AI API
- Access the Policy Section: Go to Develop > API Configurations > Policies > Request/Response Flow
- Configure Request Flow:
- Click Add Policy and select Semantic Cache
- Set Policy Name (e.g., "SemanticCache")
- Configure Threshold (typically 0.3-0.5 for normalized embeddings)
- Define JSONPath Expression to extract the query content (e.g., $.messages[-1].content)
- Configure Response Flow:
- Click Add Policy and select Semantic Cache
- Use the same Policy Name as the request flow
- Set the same Threshold value
- No JSONPath expression needed (handles cache storage only)
- Save and Deploy: Save your changes and redeploy the API
Important: The semantic cache policy must be added to both request and response flows to function properly. The request flow handles cache lookup using the JSONPath to extract content for semantic similarity checking, while the response flow handles cache storage.
Understanding WSO2's similarity matching
WSO2's semantic cache uses L2 (Euclidean) distance to measure dissimilarity between query embeddings, rather than cosine similarity. This means:
- Lower threshold values = stricter matching (more similar queries required)
- Higher threshold values = looser matching (broader range of queries match)
- Typical range: 0.0 (exact match) to 2.0 (maximum distance for normalized embeddings)
- Common thresholds: 0.3-0.5 for most use cases
For example, with a threshold of 0.35:
- Query: "What is the capital of France?" (original)
- Match: "Tell me the capital city of France" (distance: ~0.20 - cache hit)
- No match: "What's the weather in France?" (distance: ~1.5 - cache miss)
The JSONPath expression extracts the specific content from your request payload that will be compared. For chat-style APIs, $.messages[-1].content extracts the most recent message content for semantic matching.
Key features
WSO2's semantic caching implementation includes:
- Intelligent Similarity Detection: Uses embedding models to understand semantic similarity between queries
- Cost Optimization: Reduces AI provider API calls by serving cached responses for similar queries
- Performance Enhancement: Faster response times for semantically similar requests
- Multiple Embedding Providers: Support for Mistral, Azure OpenAI, and OpenAI embedding models
- Vector Database Integration: Leverages Zilliz and Milvus for efficient similarity search
- Configurable Thresholds: Fine-tune cache behavior based on your use case
- Flexible Content Extraction: JSONPath expressions allow you to target specific parts of requests
This approach eliminates the need to manage a homegrown semantic caching solution and instead allows you to get up and running quickly. For complete configuration details and advanced options, refer to the WSO2 AI Gateway documentation. You can also learn more about AI gateway capabilities in the WSO2 AI Gateway overview.
Conclusion
Semantic caching has evolved from an optimization technique to an essential component of production AI applications. For high-traffic applications, it can reduce LLM costs by 40-60% or more while delivering responses in milliseconds instead of seconds.
WSO2's AI Gateway provides production-ready semantic caching without the build and maintenance burden. The gateway handles embedding generation, vector similarity search, and cache management automatically through policy-based configuration, letting you focus on what makes your AI application unique.
Ready to reduce your LLM costs and improve response times? Explore WSO2's AI Gateway to see how semantic caching can optimize your AI applications in minutes, not months.