WHITE PAPER
12/2017
Identity Architect Ground Rules: Ten IAM Design Principles
By Prabath Siriwardena
Senior Director - Security Architecture, WSO2
Table of Contents

1. Introduction
Identity and access management (IAM) done right, could be a key catalyst in building a successful business in the era of digital transformation. IAM addresses the mission-critical needs to ensure appropriate access to resources across increasingly heterogeneous technology environments, and to meet increasingly rigorous compliance requirements. IAM as a security practice is a crucial undertaking for any enterprise. It is increasingly business-aligned and in addition to technical expertise, requires business skills.
There are multiple components in an IAM system: provisioning (or on-boarding), accounts management, identity governance, identification (or authentication), access control (or authorization) and identity federation. IAM is a broad area, hence these components can be further divided into specific sub-components. For instance, provisioning alone focuses on inbound/outbound provisioning of user accounts, just-in-time provisioning, approval workflows while accounts management talks about privileged accounts management, credential management, users/groups/roles management.
This white paper will focus more on the low-level design principles an IAM architect must consider when building an IAM infrastructure from ground-up.
2. Rule 1 - Enable Immutable Private Identifiers/Mutable Public Identifiers
In any IAM system, a user is identified by one or more identifiers. These can include a username (picked by the user), email address, phone number, insurance policy number, or any identifier that’s unique across the system. The user may pick any one of these to prove himself/herself and access the system. For example, you can login to Facebook either with your email address or phone number. You can also have multiple email addresses and can use any of them. These are your public identifiers you won’t mind sharing with others.
These public identifiers are mutable. The user should have the option to change them. You should be able to change your phone number, email address, etc. with zero impact on the system. Some systems/operators recycle email addresses and phone numbers. This could result in a case where two or more users get registered in the system with the same email address or the phone number at different times (not at the same time).
This creates the need to have a private identifier that’s immutable. The private identifier is a system generated identifier, which is unique across the system and the time is never shared with the user and is just internal to the system. You will need to have a single place in the system that maps this private identifier to one or more public identifiers of a given user. Other than this mapping table, users’ public identifiers are never used in the system for any references , rather only the private identifier is used. During a login event, the public identifier provided is matched to the corresponding private identifier and that is used to authenticate the user. All the audit logs and analytics are kept against the private identifier. To make the analytics dashboard and reports meaningful, the mapping table can be used to find a more meaningful, human readable identifier of the user only for display purposes.
Since we maintain all the internal references of a given user using an immutable identifier, changes to the public identifiers will have zero impact on the system.
Figure 1
3. Rule 2 - Decouple Core/Static Personally Identifiable Information (PII) from Transactional Data
According to NIST, Personally Identifiable Information (PII) refers to any information about an individual maintained by an agency, including any information that can be used to distinguish or trace an individual‘s identity (such as a name, social security number, date and place of birth, mother‘s maiden name, or biometric records) or any other information that is linked or linkable to an individual (such as medical, educational, financial, or employment information).
Static (or close to static) PIIs are your first name, last name, email, phone number, SSN and so on. Other transactional data that’s linkable to you are medical records, education/financial records, login patterns, etc. While building your IAM infrastructure, transactional data must be decoupled from static PIIs and those can be linked with an auto-generated, immutable system identifier, as explained in Rule 1.
This separation helps to scale transactional data independently from static PIIs. You can independently pick the storage type, which fits your requirements based on the type of data. Further, this separation addresses data privacy concerns. You do not need to worry about encrypting any transactional data, but the PIIs and the mapping table (which maps the PIIs to an autogenerated, immutable system identifier). When you are asked to delete a user, to be compliant with privacy regulations (like GDPR), you only need to worry about removing static PII and then the corresponding mapping. This will make the corresponding transactional data anonymous.
4. Rule 3 - Decouple Biometrics from Other PII
Aadhaar, a brain-child of the Indian government to secure its residents’ fundamental rights to have an unforgeable identity, is the largest collection of biometric data in the world. It has captured fingerprints and iris of more than 1 billion residents in India. In addition to biometrics, Aadhaar also collects name, date of birth, gender, address, mobile/email (optional) of every resident (not necessarily a citizen), and stores those against the corresponding fingerprints and iris patterns.
The Integrated Automated Fingerprint System (IAFIS) in the US run by the FBI is another large repository of biometrics, which includes fingerprints, facial images, and other physical characteristics, including height, weight, hair, eye color, and even scars and tattoos. The database has more than 70 million criminal records alongside 34 million civil records that law enforcement agents have available on a 24x7x365 basis.
There are two common use cases of biometrics: identification and authentication. Biometric identification answers the question “who are you” and usually applies to a situation where an organization needs to identify a person. The organization captures a biometric from that individual and then searches a biometric repository in an attempt to correctly identify the person. This is what happens in many international airports. It captures your iris and fingerprints, and tries to identify you against the record they already have in their data store.
Biometric authentication asks the question “can you prove who you are” and is predominantly related to proof of identity in digital scenarios. It does a one to one match to see whether your biometrics matches the identity of whom you claim to be. Most enterprises use biometrics to authenticate users as a second factor. One key thing we need to worry about here is how you store biometric data. Biometric enrollment and matching are done by a specialized biometric engine. The biometric engine stores biometric templates against the user. Here we have to decouple PII from biometric data and the easiest way to do this is to get the hash of the immutable private identifier (which is a pseudonym) and store it along with the biometric data. Whoever captures the biometric data will not be able to relate that to the PII of the corresponding user. Even if an attacker gets access to both the PII and biometrics data stores, he/she will still have to go through all the immutable private identifiers, hash them and then find a match. Remember though that we are encrypting the private identifier to the PII matching table, so the attacker has to gain access to the corresponding keys too, making it even more difficult for the attacker.

Figure 2
5. Rule 4 - Externalize Access Control Rules
Access control rules are a reflection of business requirements. They should be represented in a way the changes in the business requirements can be absorbed into the access control rules with minimal impact/effort. The key fundamental to make this happen is to externalize your access control rules so you have more control over them and these can evolve independently from the application code. Another important aspect is the separation of duties. In an enterprise it’s not the application developer who decides on the access control rules , neither the identity architect, but the business itself. It’s not a technical decision, but a business decision. Moreover, in a production deployment, it’s not the developers or the architects who configure access control rules, but an IAM admin or a system admin. Therefore, externalizing rules helps you to get there without any major hurdles.
Once the rules are externalized, you must think of the best way to represent them and how they are enforced. As an identity architect, you need to build an architecture for policy administration, policy enforcement, policy evaluation and policy storage. If you plan to build this from scratch, we recommend XACML as it presents a reference architecture, a policy language, and a request/response protocol. The XACML reference architecture defines a policy administration point (PAP), policy decision point (PAP), policy enforcement point (PEP), policy information point (PIP), and the interactions between them. The policy language in XACML is XML based. It’s quite rich in terms of what it can do , but it’s not fairly straightforward and requires some effort around the tooling support.
The XACML request/response model can be either XML based or JSON based — and the interaction between the PEP and PDP can be standardized via a REST API. Then again, you first need to worry about access control requirements and then decide how to represent those as policies. Prefer standards alway, but you do not need to use it just because it is a standard even if it’s an overkill to address your requirements. Also check what else around, for instance, AWS has developed their own JSON-based policy language to control access to AWS resources.
If you are going to build your own policy language (much like what AWS has), you need to clearly identify and differentiate rules from data. For example, let’s say you need to have a policy that says a doctor can only view a record of a patient, only if that patient belongs to him/her. You should not put the name of the doctor and all other patient names under him/her into the policy itself. This is the data that dynamically changes. You just need to have a sort of reference in your policy and provide some policy information points (PIPs) to interpret this, fetch the data, and feed the data into the policy engine. Once again, there is a cost of building a policy engine, so you can also think of developing your own DSL (domain specific language) and write a translator to run it on a proven XACML engine or even on a rules engine.
6. Rule 5 - Ensure Low Trust Planes Have No Write Access
Each component in a network has a trust level. The key components in an IAM deployment include the identity provider (IdP), identity store (ldap/database), metadata/policy store, a gateway (policy enforcement point), and finally the service providers. Each of these components or some of these can be in different trust planes.
It’s a not a requirement the identity provider and the identity store must be in the same trust plane. This can be the case in a larger enterprise though where you have multiple identity providers.
For example, one of the largest communication and network infrastructure services provider in the US WSO2 worked with had a core identity provider deployed over their corporate identity store. Both the identity provider and the identity store in that case were deployed on the same trust plane. This identity provider is the backbone of their corporate identity infrastructure — the single source of truth — and is managed by the corporate IT team. The project we worked on was for one of its departments , where the identity provider was deployed in a different trust plane. All the service providers/applications deployed under this department only trusted its own identity provider. The identity provider deployed at the department level (let’s say the local identity provider) was on a lower trust plane than of the corporate identity provider and also the corporate identity store. Therefore, it cannot have a direct write access to the identity provider on the high trust plane. The communication between the two identity providers were facilitated through SAML 2.0 Web SSO. All the additional user attributes required for the service providers/applications were captured centrally at the local identity provider and were JIT provisioned. Then again, even within the same department, the local identity provider and the service providers were in different trust planes. The service providers were only given read-only access to the identity provider’s APIs.
Building and designing an IAM infrastructure on different trust planes helps decentralizing responsibilities and ownership based on the level of trust.
7. Rule 6 - Decouple B2C from B2E and B2B
In B2E IAM, onboarding is a responsibility of the employer, while in a B2C it’s mostly self onboarding. In other words, for employees, it’s the HR department that initiates the employee onboarding process and remains the owner of the user accounts, while for customers , in most cases, the onboarding happens via self registration. It can be a completely new customer or an existing customer who now wants to use a company’s online services. Let me give you a few examples for the latter.
- WSO2 recently worked with a popular life insurance provider in the US. The insurance agents sell insurance policies ; to do the payments and claims online, the customer has to register via the company’s website. The customer registration form asks a minimal set of details like policy number, social security number, name, and the date of birth , and the user provided information will be automatically validated against the user data already recorded in the system (after the original policy being sold).
- Another company that sells medical equipment to individuals and medical institutes, lets them register via the company website to consume online services. As in the case of the previous example, the medical equipment is sold by sales agents and all the customer data is recorded in Salesforce. When a customer decides to register online , the data entered by the customer is verified against the data already recorded in Salesforce.
- WSO2 also worked with a company on the west coast who’s building a virtualized data center at the enterprise level. They follow the same model as explained in the previous example. They too maintain customer records in Salesforce first at the point of a sale and then thereafter the customer can register via the company’s online portal by providing the same information recorded earlier in Salesforce.
There can be several examples and variations in models used in customer onboarding. In addition to the above scenarios, there are multiple companies that WSO2 has worked with who open up their user registration to new customers. Most of these companies allow customer registrations via a known public identity provider. This vastly reduces the initial barrier for registration and there are multiple studies that confirm the significant success rate in user registration after integrating with known public identity providers (e.g. Facebook, Google, Microsoft Live).
B2E/B2B IAM is also collectively known as workforce IAM. The workforce IAM looks inward. The workforce IAM focuses on B2E (business-to-employee) and B2B (business-to-business) interactions. The goal of workforce IAM is to reduce the risk and cost associated with onboarding and off-boarding new employees, partners and suppliers, while the purpose of customer IAM (or B2C) is to help drive revenue growth by leveraging identity data to acquire and retain customers.
The key challenge in workforce IAM is to break identity silos in the enterprise and build a unified identity platform, which will result in improved productivity, security, governance, oversight, compliance, and monitoring. Ultimately, this will reduce both the risk and costs associated with all B2E and B2B interactions. Recently we worked with a large analytics firm in the US to help them migrate from their current IAM system , which is fairly ad hoc in nature, to an optimized model. The key challenge was to come up with a model to build a unified identity system across all applications. They had more than 30 identity stores used by multiple applications and the same user is duplicated in each identity store with no correlation handle. What’s important to note is that B2C, B2E, and B2B IAM models have their own design goals and challenges. There is no all-in-one solution. Moreover, you need to build these IAM models independent of each other and not share the same identity store and identity provider between the employees and customers. If you have applications that require access from both customers and employees, you need to consider a federated model.
8. Rule 7 - Ensure Persistent Pseudonyms for Attribute Sharing
One key responsibility of an identity provider running in an IAM infrastructure is to act as the single source of truth. All other components in the corporate network (and beyond) trust the assertions issued by the identity provider. These assertions can be authentication assertions, attribute assertions, or authorization assertions. Assertions are bound to the authenticated subject. What is the subject identifier the identity provider should use here, with respect to the authenticated user? To answer this question, please refer to Rule 1.
The public mutable identifiers, as the name suggests, are mutable. If you use one of those as the subject identifier, then the service provider will find it hard to correlate the user after a change in that attribute at the identity provider’s end. How about the private immutable identifier (as the subject identifier)? Once again, as the name suggests, it is supposed to be private and should not be shared outside.
The recommended approach is to use a persistent pseudonym by user or by service provider. Each user will have a different pseudonym per each service provider and is mapped to its private immutable identifier at the identity provider. Each service provider can use this pseudonym as a correlation handle. This addresses some privacy concerns too. If you share the same identifier between multiple service providers, then those service providers together can discover your behavioral/access patterns. This may be not be a key concern in a corporate environment , but will be if you are building a public identity provider.
9. Rule 8 - Standards Rule - Feel Free to Fix It , But Do Not Break It!
It’s important to note that no identity product today will gain any competitive advantage by just supporting open identity standards as that’s a given and expected by any identity product. That said, if you build an identity product that does not support open standards, you’re essentially stillborn.
Standards are not born alone - there are many committees under standards bodies, such as W3C, IETF, OpenID Foundation, OASIS, Kantara Initiative and many more that involve smart people who work tirelessly discussing the prevailing problems in the identity space, building solutions, and standardizing these. Once you define your problem, you should spend some time to see how the identity standards out there help you to build a solution. Once again, do not be driven by standards, but rather by your own problem statement, and there’s always room for improvements. If you feel your problem is not addressed properly, don’t hesitate to build a solution by fixing the problem, and if you like, you could take your solution to a standards body and see how this can be made a standard. This is how identity standards typically evolve.
Let’s look at some key standards used in the identity space today - for identity federation and single sign-on, SAML 2.0 Web SSO, OpenID Connect, WS-Federation are the prominent standards. SAML as a standard still rules , but then most new developments in the past few years have been using OpenID Connect. OpenID Connect is a standard built on top of OAuth 2.0. For fine-grained access control, the only available standard is XACML, which was discussed in detail in this paper. For provisioning, SCIM is the prominent standard and OAuth 2.0 and multiple profiles built around it are the key standards in securing APIs and for access delegation in general. The FAPI (financial APIs) working group under the OpenID Foundation is working on building a set of standards around OAuth 2.0, mostly targeting financial applications. User Managed Access, or UMA, is another prominent standard that’s being developed under the Kantara Initiative. UMA tries to build a rich, highly decoupled ecosystem around access delegation and is built on top of OAuth 2.0. Identity architects must also consider the work of JOSE working group under IETF as multiple standards like JWS (JSON Web Signature), JWE (JSON Web Encryption), JWK (JSON Web Key) are being developed under this working group.

Figure 3
10. Rule 9 - Enable Self-Expressive Credentials
This is pretty basic to discuss here, however there are multiples aspects that most people rarely worry about. Often, organizations build systems without worrying about this aspect and face challenges later when they have to upgrade their system to support a much more secure hashing algorithm.
Securing user credentials is a key aspect in any IAM infrastructure. These credentials can be just passwords or any kind of keys. For example, in OAuth 2.0, you need to worry about protecting client secrets, access tokens, and refresh tokens. There are two types of credentials that you store in an IAM infrastructure. The ones that you own (or issue) and the ones that you use. The first one is self explanatory and includes passwords and OAuth keys issued by you. The credentials that you store to access third-party systems fall into the second category. For example, the API keys to access Facebook to enable login with Facebook, or the API keys to access Salesforce/Google Apps APIs to provision users.
The first type of credentials can be secured with a salted hash and the second type should be secured with encryption. In other words, when you hash a credential, make sure to bind the hashing algorithm into the hashed credentials itself. When you try to validate the credentials, the credentials itself will be self expressive. There are many benefits to this approach - let’s say, for instance, you only have a system level hashing algorithm (this anyway you need to have). All your user passwords are hashed with the system level hashing algorithm. Now let’s say you need to change the hashing algorithm to a much more secure one. For new users it won’t be an issue as all the new credentials will be stored under the new hashing algorithm and so is the validation. All credential verification with respect to existing users will fail and there is no straightforward way of doing a bulk migration. This is the trap you fall into with this approach. If you make the credentials self expressive, then you know how to validate each of them independently. Moreover, with this approach, if you find any credentials that are stored against a hashing algorithm that differs from the system setting, then you can rehash with the new one and update the system at the point of validation.
For any hashed data, the hashing algorithm is the most important thing. For example, in 2012, LinkedIn was compromised and password data was stolen. At the time, LinkedIn was using the MD5 hashing algorithm for password storage. This was a dangerously bad idea because flaws had been discovered in MD5 as early as 1996 and, as of 2005, even its own author stopped recommending to use it. The first go-to algorithm for password storage is PBKDF2 NIST standard key derivation function. This is one-way and can be configured to process relatively slowly on purpose. GPU cracking rigs and other supercomputing resources can attempt many billions of hashes per second. When using a purposely slow algorithm with proper configuration settings, those billions of attempts per second become mere thousands of attempts per second on the same hardware.
11. Rule 10 - Consider Privilege Accounts as a Different Species
A privileged account is how administrators login in to servers, switches, firewalls, routers, database servers, and the many applications they must manage. In an IAM infrastructure, there are multiple occasions where privileged accounts are used. The database credentials, identity store credentials (active directory), IAM admin credentials (possibly accessing a web-based management console to perform IAM admin functions), and also other third-party system/service accounts (access IAM APIs to perform administrative functions) all fall under the category of privileged accounts.
Forrester estimates that 80% of security breaches involve privileged credentials. It’s understandable that after an intruder gains access to employees’ devices, they try to snoop the network and install a keylogger to get higher privilege credentials (such as root or administrator). Privileged credentials provide greater scope for stealing data en masse than individual accounts do. With privileged credentials, attackers can dump the entire database, bypass network traffic limitation, delete logs to hide their activity, and exfiltrate data easier.
Privileged Identity Management (PIM) is a key area in IAM and there are specialized vendors who build products that support PIM. When building any serious IAM infrastructure, you need to worry about how your system integrates with PIM products. It is also required to have a PIM system in place to comply with industry mandates, such as SOX, PCI-DSS, HIPAA, FISMA,BASEL III, and many others.
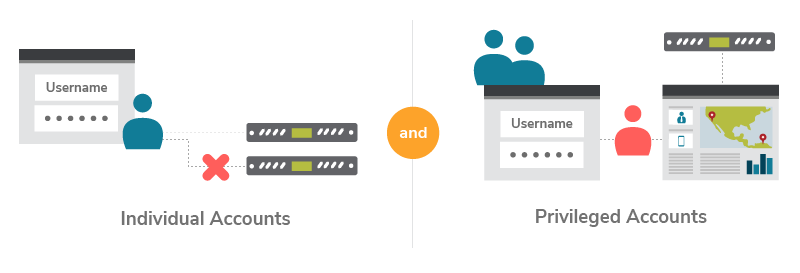
Figure 4
12. Conclusion
The objective of this paper is to cover the key fundamentals that would be helpful to an identity architect who’s looking to build an IAM infrastructure from ground-up. The rules covered here are by no means inclusive, but will provide architects with a solid foundation of key rules they must consider before getting started.
For more details about our solutions or to discuss a specific requirement