Auto Scaling with WSO2 Load Balancer

- Kathiravelu Pradeeban
- Software Engineer - WSO2
Introduction
WSO2 Load Balancer ensures high availability and scalability in the enterprise systems. WSO2 Load Balancer is used in cloud environments to balance the load across the server instances. An ideal use case of the Load Balancer is WSO2 StratosLive, where the service instances are fronted with the load balancers and the system scales automatically as the service gets more web service calls. Having the Apache Tribes Group management framework, Apache Axis2 Clustering module, Apache Synapse mediation framework, and autoscaling component as the major building blocks, WSO2 Load Balancer becomes a complete software load balancer that functions as an autoscaler and a dynamic load balancer.
Applies To
| WSO2 Load Balancer | 1.0.2 |
Content
- Auto Scaling with WSO2 Load Balancer
- How Auto Scaling Works
- Configuring Load Balancer for Auto Scaling
- Case Study - StratosLive
Auto Scaling with WSO2 Load Balancer
WSO2 Load Balancer can be configured to function as a load balancer with autoscaling on the supported infrastructure. Currently the autoscaler supports EC2 API. Thus the Load Balancer can be configured as a dynamic load balancer with autoscaling, on Amazon EC2 and the other infrastructures compatible with the EC2 API. The autoscaling component uses ec2-client, a Carbon component that functions as a client for the EC2 API and carries out the infrastructure level functionalities. Spawning/starting a new instance, terminating a running instance, managing the service groups, and mapping the elastic IPs are a few of the infrastructure related functionalities that are handled by the autoscaling component.

How Auto Scaling Works
The autoscaling component comprises of the synapse mediators AutoscaleInMediator and AutoscaleOutMediator and a Synapse Task ServiceRequestsInFlightEC2Autoscaler that functions as the load analyzer task. A system can scale up based on several factors, and hence autoscaling algorithms can easily be written considering the nature of the system. For example, Amazon's Auto Scaler API provides options to scale the system with the system properties such as Load (the timed average of the system load), CPUUtilization (utilization of the cpu at the given instance), or Latency (delay or latency in serving the service requests).
autoscaler.xml
The autoscaling configurations are defined from CARBON_HOME/repository/deployment/server/synapse-configs/tasks/autoscaler.xml
1) Task Definition
In WSO2 Load Balancer, the autoscaling algorithm to be used is defined as a Task. ServiceRequestsInFlightEC2Autoscaler is the default class that is used for the autoscaler task.
<task xmlns="http://ws.apache.org/ns/synapse" class="org.wso2.carbon.mediator.autoscale.ec2autoscale.ServiceRequestsInFlightEC2Autoscaler" name="autoscaler">
2) loadbalancer.xml pointed from autoscaler.xml
This property points to the file loadbalancer.xml for further autoscaler configuration.
<property name="configuration" value="$system:loadbalancer.xml"/>
3) Trigger Interval
The autoscaling task is triggered based on the trigger interval that is defined in the autoscaler.xml. This is given in seconds.
<trigger interval="5"/>
Autoscaler Components
- AutoscaleIn mediator - Creates a unique token and puts that into a list for each message that is received.
- AutoscaleOut mediator - Removes the relevant stored token from the list, for each of the response message that is sent.
- Load Analyzer Task - ServiceRequestsInFlightEC2Autoscaler is the load analyzer task used for the service level autoscaling as the default. It periodically checks the length of the list of messages based on the configuration parameters. Here the messages that are in flight for each of the back end service is tracked by the AutoscaleIn and AutoscaleOut mediators, as we are using the messages in flight algorithm for autoscaling.
ServiceRequestsInFlightEC2Autoscaler implements the execute() of the Synapse Task interface. Here it calls sanityCheck() that does the sanity check and autoscale() that handles the autoscaling.
Sanity Check
sanityCheck() checks the sanity of the load balancers and the services that are load balanced, whether the running application nodes and the load balancer instances meet the minimum number specified in the configurations, and the load balancers are assigned elastic IPs.
nonPrimaryLBSanityCheck() runs once on the primary load balancers and runs time to time on the secondary/non-primary load balancers as the task is executed periodically. nonPrimaryLBSanityCheck() assigns the elastic IP to the instance, if that is not assigned already. Secondary load balancers checks that a primary load balancer is running periodically. This avoids the load balancer being a single point of failure in a load balanced services architecture.
computeRunningAndPendingInstances() computes the number of instances that are running and pending. ServiceRequestsInFlightEC2Autoscaler task computes the running and pending instances for the entire system using a single EC2 API call. This reduces the number of EC2 API calls, as AWS throttles the number of requests you can make in a given time. This method will be used to find whether the running instances meet the minimum number of instances specified for the application nodes and the load balancer instances through the configuration as given in loadbalancer.xml. Instances are launched, if the specified minimum number of instances is not found.
Autoscale
autoscale() handles the autoscaling of the entire system by analyzing the load of each of the domain. This contains the algorithm - RequestsInFlight based autoscaling. If the current average of requests is higher than that can be handled by the current nodes, the system will scale up. If the current average is less than that can be handled by the (current nodes - 1), the system will scale down.

Autoscaling component spawns new instances, and once the relevant services successfully start running in the spawned instances, they will join the respective service cluster. Load Balancer starts forwarding the service calls or the requests to the newly spawned instances, once they joined the service clusters. Similarly, when the load goes down, the autoscaling component terminates the under-utilized service instances, after serving the requests that are already routed to those instances.
Configuring Load Balancer for Auto Scaling
This post assumes that the reader is familiar at configuring the WSO2 Load Balancer without autoscaling, and has configured the system already with the load balancer. Hence this post focuses on setting up the load balancer with autoscaling. If you are a newbie to setting up WSO2 Servers proxied by WSO2 Load Balancer, please read the blog post, How to setup WSO2 Elastic Load Balancer to configure WSO2 Load Balancer without autoscaling.
Autoscale Mediators
autoscaleIn and autoscaleOut mediators are the mediators involved in autoscaling as we discussed above. As with the other synapse mediators, the autoscaling mediators should be defined in the main sequence of the synapse configuration, if you are going to use autoscaling. Load Balancer-1.0.x comes with these mediators defined at the main sequence, which can be found at $CARBON_HOME/repository/deployment/server/synapse-configs/sequences/main.xml. Hence you will need to modify main.xml, only if you are configuring the load balancer without autoscaling.
autoscaleIn mediator is defined as an in mediator. It gets the configurations from loadbalancer.xml, which is the single file that should be configured for autoscaling, once you have already got a system that is set up for load balancing.
<autoscaleIn configuration="$system:loadbalancer.xml"/>
Similarly autoscaleOut mediator is defined as an out mediator.
<autoscaleOut/>
loadbalancer.xml
loadbalancer.xml contains the service cluster configurations for the respective services to be load balanced and the load balancer itself. Here the service-awareness of the load balancer makes it possible to manage the load across multiple service clusters. The properties given in loadbalancer.xml is used to provide the required configurations and customizations for autoscaling and load balancing. These configurations can also be taken from the system properties as shown below.
1) Properties common for all the instances
1.1) ec2AccessKey
The property 'ec2AccessKey' is used to provide the EC2 Access Key of the instance.
<property name="ec2AccessKey" value="${AWS_ACCESS_KEY}"/>
1.2) ec2PrivateKey
The certificate is defined by the properties 'ec2PrivateKey'.
<property name="ec2PrivateKey" value="${AWS_PRIVATE_KEY}"/>
1.3) sshKey
The ssh key pair is defined by 'sshKey'.
<property name="sshKey" value="stratos-1.0.0-keypair"/>
1.4) instanceMgtEPR
'instanceMgtEPR' is the end point reference of the web service that is called for the management of the instances.
<property name="instanceMgtEPR" value="https://ec2.amazonaws.com/"/>
1.5) disableApiTermination
The 'disableApiTermination' property is set to true by default, and is recommended to leave as it is. This prevents terminating the instances via the AWS API calls.
<property name="disableApiTermination" value="true"/>
1.6) enableMonitoring
The 'enableMonitoring' property can be turned on, if it is preferred to monitor the instances.
<property name="enableMonitoring" value="false"/>
2) Configurations for the load balancer service group
These are defined under
<loadBalancer> .. </loadBalancer>
2.1) securityGroups
The service group that the load balancer belongs to is defined by the property 'securityGroups'. The security group will differ for each of the service that is load balanced as well as the load balancers. Autoscaler uses this property to identify the members of the same cluster.
<property name="securityGroups" value="stratos-appserver-lb"/>
2.2) instanceType
'instanceType' defines the EC2 instance type of the instance - whether they are m1.small, m1.large, or m1.xlarge (extra large).
<property name="instanceType" value="m1.large"/>
2.3) instances
The property, 'instances' defines the number of the load balancer instances. Multiple load balancers are used to prevent the single point of failure - by providing a primary and a secondary load balancer.
<property name="instances" value="1"/>
2.4) elasticIP
Elastic IP address for the load balancer is defined by the property, 'elasticIP'. We will be able to access the service, by accessing the elastic IP of the load balancer. The load balancer picks the value of the elastic IP from the system property ELASTIC_IP.
<property name="elasticIP" value="${ELASTIC_IP}"/>
In a public cloud, elastic IPs are public (IPV4) internet addresses, which is a scarce resource. Hence it is recommended to use the elastic IPs only to the load balancer instances that to be exposed to the public, and all the services that are communicated private should be associated to private IP addresses for an efficient use of this resource. Amazon EC2 provides 5 IP addresses by default for each customer, which of course can be increased by sending a request to increase elastic IP address limit.
2.5) availabilityZone
This defines in which availability zone the spawned instances should be.
<property name="availabilityZone" value="us-east-1c"/>
2.6) payload
The file that is defined by 'payload' is uploaded to the spawned instances. This is often a zip archive, that extracts itself into the spawned instances.
<property name="payload" value="/mnt/payload.zip"/>
payload.zip contains the necessary files such as the public and private keys, certificates, and the launch-params (file with the launch parameters) to download and start a load balancer instance in the spawned instances.
The launch-params includes the details for the newly spawned instances to function as the other instances. More information on this can be found from the EC2 documentations.
Sample Launch Parameters
Given below is a sample launch-params, that is used in StratosLive by the load balancer of the Application Server service.
AWS_ACCESS_KEY_ID=XXXXXXXXXXXX,AWS_SECRET_ACCESS_KEY=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx, AMI_ID=ami-xxxxxxxxx,ELASTIC_IP=xxx.xx.xxx.xxx, PRODUCT_MODIFICATIONS_PATH_S3=s3://wso2-stratos-conf-1.5.2/appserver/, COMMON_MODIFICATIONS_PATH_S3=s3://wso2-stratos-conf-1.5.2/stratos/, PRODUCT_PATH_S3=s3://wso2-stratos-products-1.5.2,PRODUCT_NAME=wso2stratos-as-1.5.2, SERVER_NAME=appserver.stratoslive.wso2.com, HTTP_PORT=9763,HTTPS_PORT=9443,STARTUP_DELAY=0;60
We will look more into these launch-params now.
Credentials
The credentials - access key ID and the secret access key are given to access the aws account.
S3 Locations
The service zip and the common modifications or patches are stored in an S3 bucket. The locations are given by a few properties in the launch-params shown above.
- PRODUCT_MODIFICATIONS_PATH_S3 - Points to the product specific changes, files, or patches are uploaded to a specific location.
- COMMON_MODIFICATIONS_PATH_S3 - Points to the patches and changes common to all the servers.
- PRODUCT_PATH_S3 - Points to the location where the relevant Stratos service zips are available.
- STARTUP_DELAY - Given in seconds. Provides some time to start the service that is downloaded on the newly spawned instance, such that it will join the service cluster and be available as a new service instance.
Apart from these, PRODUCT_NAME, SERVER_NAME, HTTP_PORT, and HTTPS_PORT for the application are also given.
3) Configurations for the application groups
These are defined under
<services> .. </services>
These too should be configured as we configured the properties for the load balancers above.
We define the default values of the properties for all the services under
<defaults> .. </defaults>
Some of these properties - such as the payload, host, and domain - will be specific to a particular service group, and should be defined separately for each of the services, under
<service> .. </service>
Properties applicable to all the instances
payload, availabilityZone, securityGroups, and instanceType are a few properties that are not specific to the application instances. We have already discussed about these properties when setting the load balancer properties above.
Properties specific to the application instances
These properties are specific to the application clusters, and are not applicable to the load balacer instances. We will discuss about these properties now.
3.1) minAppInstances
The property 'minAppInstances' shows the minimum of the application instances that should always be running in the system. By default, the minimum of all the application instances are set to 1, where we may go for a higher value for the services that are of high demand all the time, such that we will have multiple instances all the time serving the higher load.
<property name="minAppInstances" value="1"/>
3.2) maxAppInstances
'maxAppInstances' defines the upper limit of the application instances. The respective service can scale up till it reaches the number of instances defined here.
<property name="maxAppInstances" value="5"/>
3.3) queueLengthPerNode
The property 'queueLengthPerNode' provides the maximum length of the message queue per node.
<property name="queueLengthPerNode" value="400"/>
3.4) roundsToAverage
The property 'roundsToAverage' indicates the number of attempts to be made before the scaling the system up or down. When it comes to scaling down, the algorithm makes sure that it doesn't terminate an instance that is just spawned. This is because the spawned instances are billed for an hour. Hence, even if we don't have much load, it makes sense to wait for a considerable amount (say 58 minutes) of time before terminating the instances.
<property name="roundsToAverage" value="10"/>
3.5) instancesPerScaleUp
This defines how many instances should be scaled up for each time. By default, this is set to '1', such that a single instance is spawned whenever the system scales. However, this too can be changed such that multiple instances will be spawned each time the system scales up. However it may not be cost-effective to set this to a higher value.
<property name="instancesPerScaleUp" value="1"/>
3.6) messageExpiryTime
messageExpiryTime defines how long the message can stay without getting expired.
<property name="messageExpiryTime" value="60000"/>
Properties specific to a particular service group
Properties such as hosts and domain are unique to a particular service group, among all the service groups that are load balanced by the given load balancer. We should note that we can use a single load balancer set up with multiple service groups, such as Application Server, Enterprise Service Bus, Business Process Server, etc.
Here we also define the properties such as payload and availabilityZone, if they differ from the default values provided under
<defaults> .. </defaults>
Hence these properties should be defined under
<service>.. </service>
for each of the services.
3.7) hosts
'hosts' defines the hosts of the service that to be load balanced. These will be used as the access point or url to access the respective service.
Multiple hosts can be defined under
<hosts> .. </hosts>
Given below is a sample hosts configurations for the application server service
<hosts> <host>appserver.cloud-test.wso2.com</host> <host>as.cloud-test.wso2.com</host> </hosts>
3.8) domain
Like the EC2 autoscaler uses the security groups to identify the service groups, 'domain' is used by the load balancer (ServiceDynamicLoadBalanceEndpoint) to correctly identify the clusters of the load balanced services.
<domain>wso2.manager.domain</domain>
Case Study - StratosLive
WSO2 Load Balancer is used in production as a dynamic load balancer and autoscaler, as a complete software load balancer product. It is a stripped down version of WSO2 Enterprise Service Bus, containing only the components that are required for load balancing. WSO2 StratosLive can be considered a user scenario with WSO2 Load Balancer in production.
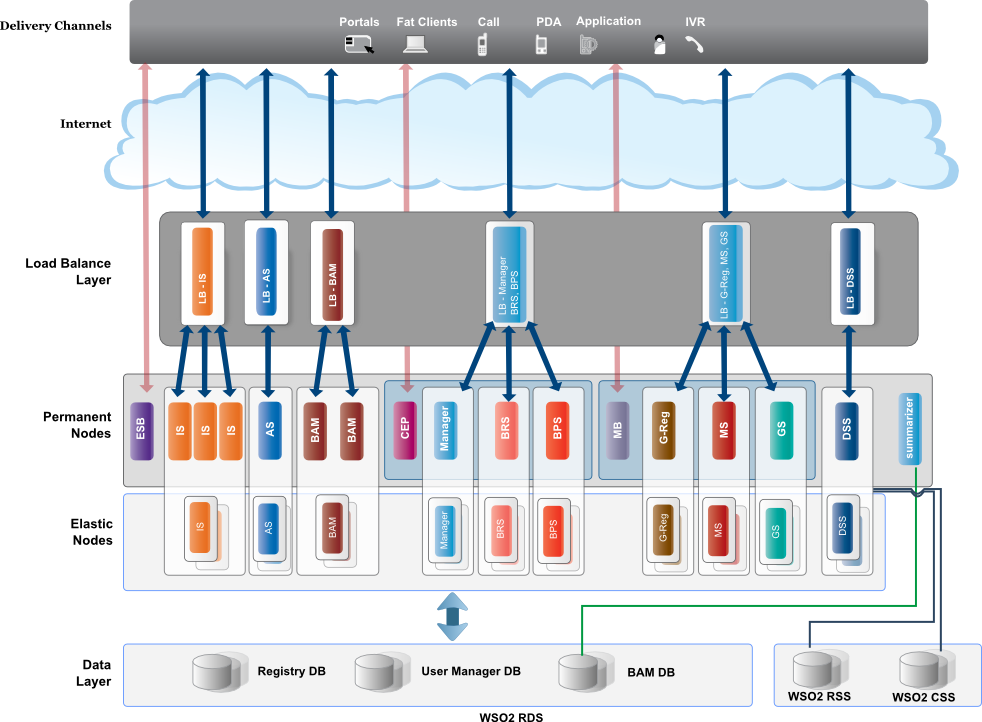
Multiple service groups are proxied by WSO2 Load Balancers. Some of the services have more than one instances to start with, to withstand the higher load. The system automatically scales according to the load that goes high and low. WSO2 Load Balancer is configured such that the permanent or the initial nodes are not terminated when the load goes high. The nodes that are spawned by the load balancer to handle the higher load will be terminated, when the load goes low. Hence, it becomes possible to have different services to run on a single instance, for the instances that are 'permanent', while the spawned instances will have a single carbon server instance.
Resources
Blog posts
Auto Scaling with WSO2 Load Balancer
WSO2 StratosLive - An Enterprise Ready Java PaaS
Auto Scaling with Amazon EC2 - I
Auto Scaling with Amazon EC2 - II
WSO2 Load Balancer - how it works
Moving from a 'Platform' to the 'Platform-as-a-Service' ~ What is it all about?
Getting Started with WSO2 Cloud Virtual Machines for Amazon EC2
Auto scaling web services on Amazon EC2
Summer School 2011 - Platform-as-a-Service: The WSO2 Way
Building SaaS for SMEs on WSO2 PaaS - Wednesday, 9th November 2011
Author
Kathiravelu Pradeeban, Software Engineer.