WHITE PAPER
04/2017
Video Analytics: Technologies and Use Cases
By Anusha Jayasundara, Software Engineer, WSO2 &
Miyuru Dayarathna, Senior Technical Lead, WSO2
Table of Contents
1. Introduction
Data is at the heart of decision making in any organization. And while data is often available, the sheer volume and frequency can be overwhelming for the respective enterprise to form a complete picture. The challenge lies in translating data into actionable insight.
Analytics harnesses the power of big data and enables enterprises to make better decisions, create innovative products, understand pain points and optimization, and gain advantages in today’s markets. One such method of sourcing data is via video analytics.
Technology developments have prompted machines to take over routines tasks, making the lives of people much easier. We've built vehicles that can solve transportation problems, built telephones to make communication easier, etc. Yet, the world is sparingly instrumented. And even though the Internet of Things (IoT) boasts a promising future, it is at best five years away.
We often forget that we have a ubiquitous sensor that covers most of the world: the camera. Cameras are relatively inexpensive and widely deployed. If we can extract high-level information from camera feeds, we gain access into a new range of use cases, such as automated surveillance, and traffic control. This topic is currently very popular in the research community. A recent report by Mckinsey & Company forecasts that video-based analytical applications will be of high importance in fields such as city, retail, vehicle, and worksite settings by 2020 [1].
This white paper will discuss the concept and technology behind video processing, a reference architecture to build a system that can extract high-level information from camera feeds, and some use cases of real-world applications.
Video processing is a technique that can be considered as a milestone of achieving intelligence in the computer vision field. As humans can see the world, computers also do so through cameras. But even though the cameras can see the world, they do not have the ability to understand the world as humans do. Video processing can be described as an initiative for solving this problem by bridging the gaps.
There are many approaches for video processing. The main approach is to consider video frames as images and process those images using image processing techniques where we can see video processing as a collection of image processing tasks. For example, the background can be subtracted from the foreground by considering a sequence of N video frames as images and by taking the statistical average of the continuous image sequence [10].
In a slightly more advanced version, we may also consider audio data associated with each and every video frame image. For example, joint processing of video and audio signals captured from a talking person can provide a number of audiovisual speech processing applications for human-computer interaction [12]. In this paper, we will focus only on the main approach, i.e. treating video frames as images.
Video processing is not one task, but a result of a collection of subtasks. In video processing, a video will be read frame by frame, and for each frame, image processing will be applied to extract the features from that frame. To extract features, many filters have to be applied to the image. All these tasks are performed as mathematical functions as doing this manually without using a specific library is a very painful task.
There are several image processing libraries and here we'll consider two of them:
OpenCV is an open source computer vision and machine learning library that was specially developed for this kind of image processing and video processing tasks [2]. Multiple image processing algorithms have been implemented in OpenCV that can be directly used with Java, C++ and Python [2].
Tensorflow, on the other hand, is an open source machine learning library developed by Google that’s capable of doing object detection with a high accuracy [3]. It uses neural network-based approaches to do the learning parts and has the ability to retrain on top of pre-trained models obtained from image databases like ImageNet [4] and AlexNet [5].
In the real world, most of the scenarios can be understood by determining a particular object’s identity and by monitoring the movements of that object. This can be applied to the computer vision as well. Video processing can be recognized as a combination of three main tasks:
- Object detection
- Object/character recognition
- Object tracking
The human eye can differentiate a bird and a plane at a glance; likewise, machines can be trained to do that using object detection models, such as Tensorflow models and OpenCV cascades. Trained model can be used to detect the object in a video frame. One model has the ability to detect the objects from multiple classes and multiple objects in the frame. This can be mentioned as the foundation of computer vision because for all other cases, object detection output will be used as an input.
Object recognition is an extended version of object detection that uses object detection in the initial stage, then maps the detected image into a known related sample dataset to match the features and try to recognize a unique object. Object recognition is widely used for face recognition, number plate recognition, and handwriting recognition.
Object tracking is a slightly more advanced scenario and can be used to monitor object behavior. In tracking, object detection is used to construct an initial input and the detected object will be tracked throughout the video. Object tracking can be considered as a complex process due to several reasons. If considered a person, it is very challenging due to the perceptual details and interferences, such as poses, lighting conditions, and illuminations. There are several object tracking algorithms and methods that can be used to track a detected object.
A real-life system that employs image processing, such as a surveillance system, will need to do much more than image processing. Such a system should collect data from video feeds, apply video processing, apply business logic, manage business logic, let the user see the interesting data through a dashboard, generate and manage alerts, and manage equipment providing video feeds. Figure 1 depicts a reference architecture that shows how to built such a system.

Figure 1: Reference Architecture for Video Analytics
As illustrated in Figure 1, the video processing layer grabs video streams from video streaming devices such as CCTV cameras, traffic cameras, online video feeds, or any other video source using real-time streaming protocol (RTSP) [6] or HTTP. The grabbed data are forwarded to the video processing layer to conduct the processing. Next, the processed results are sent to the event processor where all the input gets filtered and processed to extract the meaningful events. The user interface and dashboard layer outputs the final results in a readable and understandable manner. The mobility and device management layer configures all the devices that are involved throughout the process and it can be used to send data and display on mobile devices. Identity and access management secures communication throughout the whole process and manages the system’s security and authentication requirements.
If you implement the above reference architecture with WSO2’s technology capabilities it can be mapped as follows (Figure 2). For data processing we use WSO2 Stream Processor [7] which is a powerful analytics product that can process data streams in real time. WSO2 Stream Processor has the capability of presenting the processed data through analytical dashboard in a very attractive manner. So we used this to present the processed data to user. WSO2 Identity Server (IS) [8] is used for security and authentication purposes.
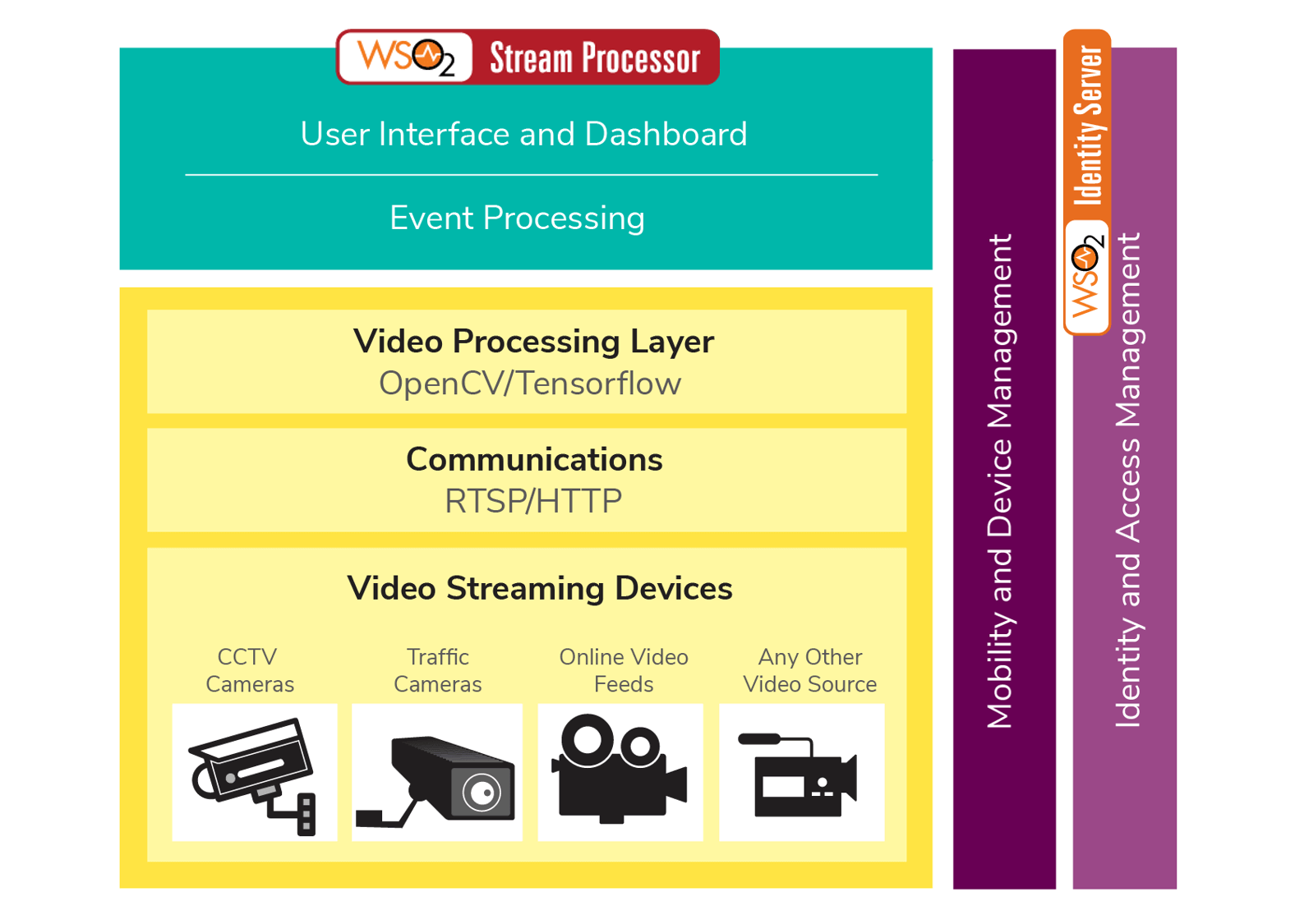
Figure 2: Mapped Reference Architecture to WSO2 Products
To further understand the reference architecture, let’s look at a concrete video processing example.
According to Airport Council International (ACI) records most airports have around 20 aircraft movements per hour. In peak hours, the rate spikes to one movement per minute. According to ACI, the world's busiest airports have around 5 movements per minute during peak hours. After a plane lands, the location of the plane should be monitored in order to control ground traffic in the airport. This is normally done by communicating with the pilot, and tracking movement via CCTV cameras that cover almost every inch of the airport. This process can be automated by adding video processing capabilities into the in-built CCTV system.
A plane detection scenario was implemented as a sample solution for video processing. This solution was developed using OpenCV and the plane recognition part was done using a Cascade Classifier, which was trained using OpenCV. For this solution, two of the above mentioned tasks (object detection and the object tracking) have been used. Even though we only used OpenCV in this use case, we can repeat the same by using Tensorflow as well.
Cascading is an ensemble learning technique that concatenates several classifiers in a multi stage manner [9]. Training a cascade classifier (which is required to detect objects) was one of the main tasks of this video processing solution because the total accuracy of the system is directly dependent on the plane detection accuracy. Therefore, a customized data set with around 4000 images of planes was used to train the cascade. It took nearly a week to train a considerably accurate cascade by using a machine that has a 16 core Intel Xeon 2.30GHz processor and 64GB of RAM.
By using the trained cascade, an application was developed with the ability to detect planes and point out the exact location of the plane in the frame by drawing a box around the plane. This application was developed to detect the status of a plane that lands at an airport. The status of the plane is identified by tracking the movement and size of the detected plane.

Figure 3: Detection of the arriving plane
To process the extracted data the size of the detected bounding box, frame ID, and timestamp were sent to WSO2 Stream Processor. Then, using Siddhi queries, we filtered the data and identified the plane’s arrival time, current state of the plane, whether it is approaching to the terminal or docked in the terminal. Figure 3 displays a scenario where a plane is arriving at the terminal. The developed system is deployed as five components, as shown in the deployment diagram in Figure 4. The first component is the Video Feed Output from a CCTV Server. This component streams the real-time video feed to the Plane Identification Engine. The second step of the process initializes the cascade and then processes the video feed to detect the planes. Then for each frame, FrameID, Time,PlaneDetected counter and the PlaneState is sent to WSO2 Stream Processor as a HTTP POST request. The following Siddhi query is a one simple query we used to generate the graph shown in Figure 5.
- From InputStream[PlaneDetected==True]
- select FrameID,PlaneDetected,PlaneState
- insert into StateStream
In the third step, WSO2 Stream Processor processes the data and determines the plane activity. Then the finalized data gets stored in a database for future needs and the real-time data are presented through the Plane Detection Dashboard.
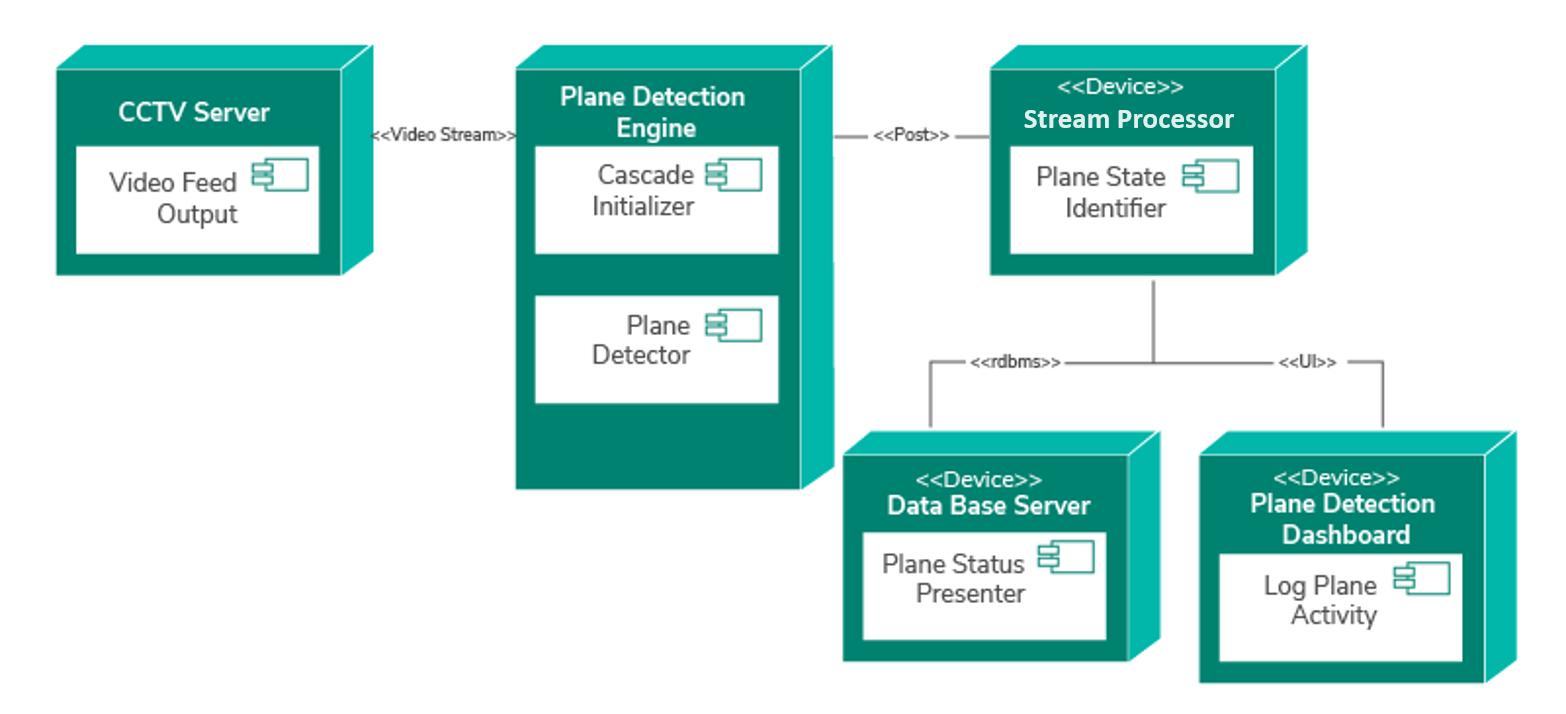
Figure 4: Deployment diagram of the plane detection application

Figure 5: State of the plane with respect to the frame ID
Figure 5 shows a graph that displays the real-time state of a plane. The dashboard can be configured in any manner where one can display the plane’s state with respect to the timestamp or frame ID.
Implementation is available on our git repository as open source software [11]. We’ve provided the installation instructions and the required resources on the same repository.
The above mentioned reference architecture can be used in many different use cases, such as traffic monitoring, security, and surveillance. Under traffic monitoring, video processing can be used to detect vehicles, control traffic by monitoring vehicle density, and even used to track a vehicle by reading the license plate of a vehicle. Moreover, the same model can be used to monitor speeding vehicles. Video feeds from traffic cameras can be used as inputs to the system.
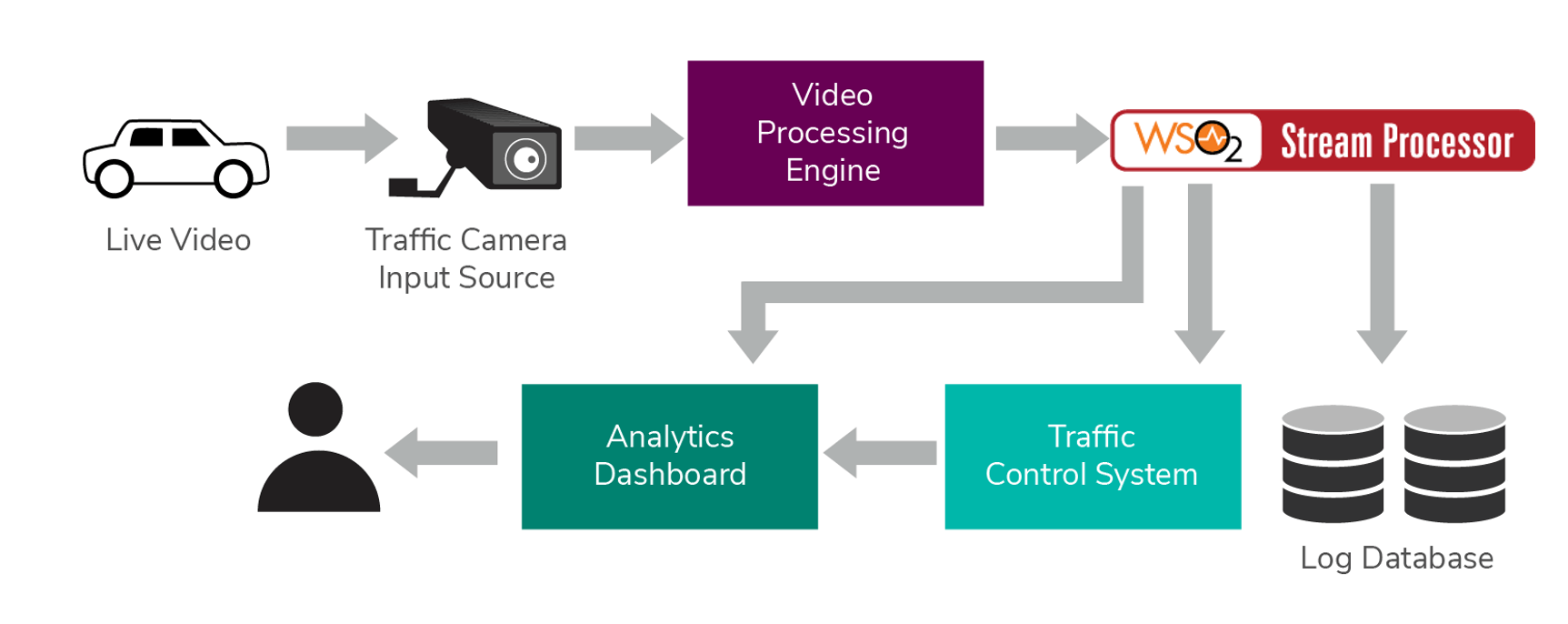
Figure 6: Overview of the Traffic Controlling System
Figure 6 elaborates how video processing can be deployed in a traffic control system. Live video feeds that are grabbed from the available traffic cameras can be used as the input to the system. The video processing engine then processes the video and the extracted data is sent to WSO2 Stream Processor to process. According to the processed data, the traffic control system will control the devices that are connected to it. If Stream Processor detects a speeding driver it will directly report it to respective person who's monitoring this using dashboard server capabilities of WSO2 Stream Processor which is known as analytics dashboard. Overall progress also gets reported to the end user and will be logged in a separate database.
As discussed in the above case study, this can be used to monitor public transport services like bus services, train services, and cab services as well. We list down three concrete use cases of transport monitoring conducted via video processing below. In those scenarios, the implementation shown in Figure 6 can be used with the relevant model to detect objects.
- Vehicle Traffic Detection is one of the key example use cases of video-based transport monitoring. In such a scenario, video processing can be applied to observe the traffic flow speed on highways that could be used to predict travel time, dynamically calculate toll values, etc. The video image sequence captured from CCTV cameras are analyzed using a point detection and tracking methodology, such as Harris-Stephen Corner interest point detector [13], SIFT detector [14], etc. The number of vehicles detected from each frame is communicated externally as the output.
- Special Incidence Detection is another example use case of video-based transport monitoring. Videos obtained from CCTV cameras can be used to detect road accidents, vehicle breakdowns, bad road conditions, etc. Level spacing curves are derived for traffic flow of each lane and the high-level modification of the curves indicates the occurrence of an accident [15].
- Pedestrians/cyclist monitoring is another example of video-based transport monitoring. Information, such as direction of motion, pedestrian/cyclist density, average speed, etc. can be used to enhance safety measures, design of urban intersections and signalized crossings, roadside advertising, heating and ventilation in public spaces, etc. For example, in such scenarios the dimensional change that takes place in each and every pedestrian’s/cyclist’s bounding box in the video stream can be used to estimate their direction of movement.
Surveillance is a vast area that mostly goes with security. The main purpose of surveillance is to monitor the behaviors, activities, and other changing information in order to protect or manage people. A video processing system that has the capability of surveillance can be easily implemented using the above reference architecture. Such a system is useful not only for surveillance purposes, but for security purposes as well. Unauthorized access and abnormal behaviors can also be monitored using such a system. Some key use cases of video based security and surveillance are as follows:
- Access control is one of the primary use cases of video processing-based surveillance. A person who enters to a premises can be uniquely identified via CCTV video streams through detecting his/her face. He/she can be assigned a unique identifier within the system with an authorization level to access different areas of the premise. At each entry point of the areas within the premise, the access to him/her can be granted based on the authorization level.
- Health status monitoring of patients in hospitals is another application of surveillance [18]. For example, the video stream captured from a camera aimed at an infant could be processed using an Eulerian video magnification and an optical flow algorithm to detect the infant’s respiratory rate. Specifically, the breathing frequency can be found by calculating the short-time Fourier transform (STFT) on the extracted information [17].
- Intrusion detection via video processing is a key application of security. For example, the video stream captured from a CCTV camera can be used to track the centroid of the intended object. If the centroid is within the specific area then that particular object is identified as an intruder [19].
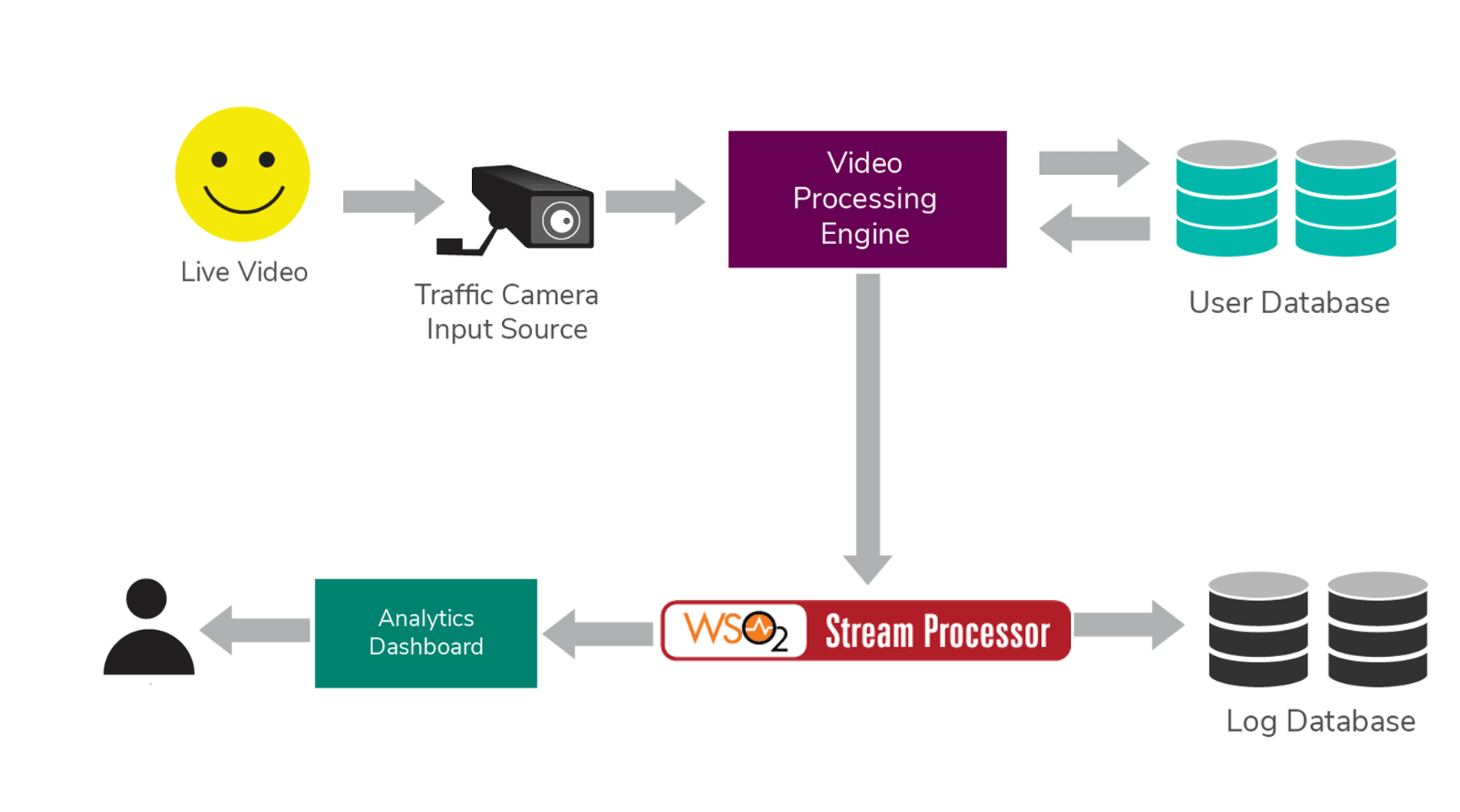
Figure 7: Overview of Security and Surveillance System
Figure 7 shows a system where surveillance and security have been implemented following the above-mentioned reference architecture. Video data is grabbed from the CCTV cameras. The video processing engine processes the video frames, detects the available faces, and cross checks the features with the available user database. Then the extracted data is sent to WSO2 Stream Processor to be processed. User movement and behaviors are logged into the log database and real-time analysis results are forwarded to the user via analytics dashboard.
Video processing can take surveillance and other monitoring tasks to a whole new level, reducing time, money, and human effort; in turn, this makes industries more secure, reliable, and consistent. This paper described the methodologies for extracting high-level information from camera feeds, such as CCTV, traffic cameras, online video feeds, etc. and also discussed how these can be applied in real-world use cases. Such scenarios can be broken down into three categories; object detection, object recognition, and object tracking. We generalized the these categories and developed a reference architecture to manipulate the generalized case. Using this reference architecture, we demonstrated how we can meet the requirements of these real-world scenarios with the WSO2 product stack.
Furthermore, we presented a real-world application of plane detection that we developed as a proof of concept of the methodologies discussed in this paper. The application detects the status of a plane that has landed at an airport by analyzing CCTV video streams. We also discussed three main use cases of video processing, i.e. traffic monitoring, security, and surveillance, and described multiple ways of how such use cases are implemented. It should be noted that WSO2's video analytics platform’s capabilities are not limited to the above-mentioned use cases and can also equally be applied virtually in any use case where video processing is required.
- [1] V. Ganesan, Y. Ji, M. Patel "Video meets the Internet of Things". [Online].Available: https://www.mckinsey.com/industries/high-tech/our-insights/video-meets-the-internet-of-things
- [2] OpenCV.org,'About OpenCV',2016.[Online]. Available: https://opencv.org/about.html
- [3] Tensorflow.org,'About Tensorflow',[Online].Available: https://www.tensorflow.org/
- [4] ImageNet.org, 'Image Net',[Online].Available: https://www.image-net.org/
- [5] A. Krizhevsky, I. Sutskever, G.E Hinton "ImageNet Classification with Deep Convolutional Neural Networks" in Neural Information Processing Systems Conference 2012.
- [6] Henning Schulzrinne, RTSP:Real-Time Streaming Protocol (RTSP), https://www.cs.columbia.edu/~hgs/rtsp/
- [7] WSO2.com,'WSO2 Stream Processor'.[Online]. Available: https://wso2.com/analytics/
- [8] WSO2.com,'WSO2 Identity Server',[Online].Available: https://wso2.com/products/identity-server/
- [9] Gama, J., & Brazdil, P. (2000). Cascade generalization. Machine Learning, 41(3), 315-343
- [10] Kuihe Yang, Zhiming Cai, Lingling Zhao (2013), Algorithm Research on Moving Object Detection of Surveillance Video Sequence, Optics and Photonics Journal, pp. 308-312.
- [11] Github.com, OpenCV_PlaneDetection, [Online]. Available https://github.com/wso2-incubator/video-image-preprocessing-wso2.git
- [12] Bovik, A.C. (2010), Handbook of Image and Video Processing, Elsevier Science, Pp.1282-1285
- [13] Chris Harris and Mike Stephens (1988), A combined corner and edge detector, In Proc. of Fourth Alvey Vision Conference, pp.147-151.
- [14] Lowe, D. G. (2004). Distinctive image features from scale-invariant keypoints. International journal of computer vision, 60(2), 91-110.
-
[15] Jeong Lee (2014), CCTV-Aided Accident Detection System on Four Lane Highway with
Calogero-Moser System, https://ocean.kisti.re.kr/downfile/volume/kics/GCSHCI/2014/
v39Cn3/GCSHCI_2014_v39Cn3_255.pdf , Korea Information and Communications
Society, Vol.39C No.03, pp. 255-263. -
[16] Yegor Malinovskiy (2008), Yao Jan Wu, Yinhai Wang, Video-based monitoring of
pedestrian movements at signalized intersections, [Online]. Available,
https://arizona.pure.elsevier.com/en/publications/video-based-
monitoring-of-pedestrian-movements-at-signalized-inte -
[17] Koolen, Ninah, Olivier Decroupet, Anneleen Dereymaeker, Katrien Jansen, Jan Vervisch,
Vladimir Matic, Bart Vanrumste, Gunnar Naulaers, Sabine Van Huffel, and Maarten De
Vos. "Automated Respiration Detection from Neonatal Video Data." In ICPRAM (2), pp.
164-169. 2015. -
[18] K. S. Tan, R. Saatchi, H. Elphick and D. Burke, "Real-time vision based respiration
monitoring system," 2010 7th International Symposium on Communication Systems,
Networks & Digital Signal Processing (CSNDSP 2010), Newcastle upon Tyne, 2010, pp.
770-774. -
[19] H. Chen, D. Chen and X. Wang, "Intrusion detection of specific area based on video,"
2016 9th International Congress on Image and Signal Processing, BioMedical
Engineering and Informatics (CISP-BMEI), Datong, 2016, pp. 23-29.
For more details about our solutions or to discuss a specific requirement