Kubernetes Autoscaling in the Real World: Going Beyond HPA to Keda
-
By Srinath Perera
- 24 Feb, 2022

Photo by Sandro Katalina
Overview
This article describes our experience in setting up autoscaling with resource-constrained containers in an integration platform as a service (iPaaS) environment, where the horizontal pod autoscaler kept autoscaling too soon, leading to poor throughput per pod value and resource wastage. We were able to reach the expected behaviour by switching to KEDA while using the default CPU-based autoscale policy. This post discusses our experiments and results.
Introduction
Autoscaling intelligently adds or removes resources to the system as needed. Its goal is to respond to change in load conditions faster than with human intervention and to free up system admins from constantly keeping a close eye on the deployment.
We define an autoscaling algorithm as viable when it can behave close to or better than a competent system administrator.
We will focus on autoscaling in Kubernetes environments. Kubernetes is increasingly becoming the de facto deployment environment because it helps us scale our deployments with ease. Kubernetes includes an autoscaler known as “horizontal pod autoscaling (HPA)”, which is a feedback control loop that calculates the required pods during each time period. The algorithm used to calculate the required pods compares a CURRENT_METRIC to a TARGET_METRIC. The algorithm is described in detail here. For example, if we used CPU-based scaling, the CURRENT_METRIC would be the current CPU utilization percentage and the TARGET_METRIC would be a target metric defined by the user. The algorithm will autoscale when the target and current metrics do not match, and, by doing so, will bring those metrics closer.
We observed that our k8s environment autoscaled too soon with heavy load, and we designed the following experiment to verify the behaviour.
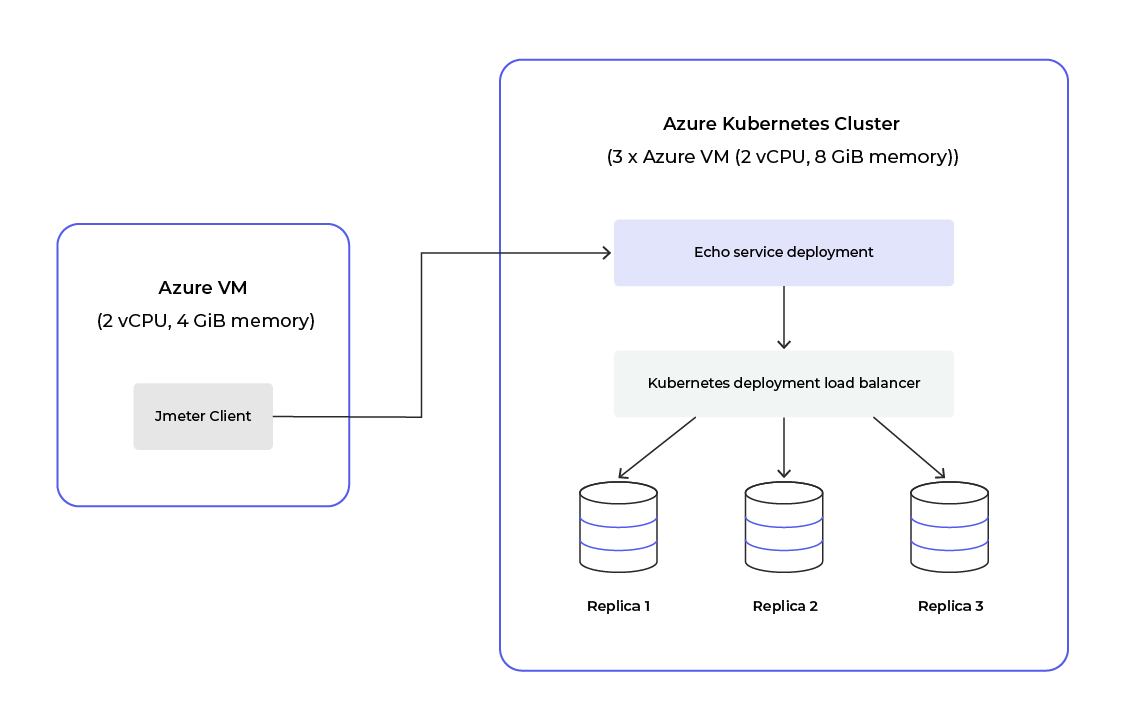
Diagram 1: Test setup
We used an echo service as the test application, which echoes the request it received back, written in Go. You can find the code from the Go Echo service
We used the following configurations for the test and while changing concurrency (independent variable), while measuring the system’s throughput and latency while HPA handles autoscaling.
|
CPU (Each Pod) |
100m (100 millicores) |
|
RAM (Each Pod) |
128 MiB |
|
Max Replicas |
16 |
|
Duration (Each concurrency) |
300 seconds |
|
Concurrency |
1, 10, 25, 50, 75, 100, 125, 150, 175, 200 |
|
Cooldown period (after each iteration) |
300 seconds |
|
Request body payload |
“Hello” |
Results and Observations
As shown in the Figure below, HPA creates more replicas than required. The TPS per replica on average was much lower than if we manually scaled the app to two deployments.

Graph 1
Furthermore, the auto scaling algorithm (red and orange) performs much worse compared to the manually scaled scenario (green).
Most likely this is caused due to high CPU behavior of the pods. However, containers in most environments will, by design, run close to CPU limits to economize; therefore, this auto scaling algorithm combined with only CPU usage, such as HPA, is not viable as per our definition of autoscaling.
Meet KEDA-HTTP
Next, we tried out KEDA as it supports many metrics and we can add custom scalers.
Kubernetes event-driven autoscaling (KEDA) enables us to scale based on other metrics or events such as HTTP Queue length, data collected from Prometheus, etc. You can find out more about KEDA here
KEDA-HTTP performs HTTP queue event based autoscaling. You can find instructions to install and set up here
High-level architecture diagram :

Diagram 2: KEDA-HTTP high level architecture
When the system receives a request, it is first received by ingress and then sent to the interceptor. The interceptor includes an in-memory queue for each service that is being scaled. KEDA-HTTP keeps track of the length of this in-memory queue. The External Scaler Service sends the current request queue value and a user defined target request queue value to KEDA, which will be fed to the HPA.
The HPA control loop works as before, but using the request queue length instead of CPU usage.
Then we repeated our experiment and the chart below shows our results :

Graph 2
However, the TPS / Replica is much lower when using KEDA-HTTP contrary to our expectations. Digging deeper into this issue we found a bug in the interceptor of KEDA-HTTP which was eventually fixed with this PR here.
Finally we repeated our experiment again after the interceptor fix and the chart below shows our new results :

Graph 3
As shown by the chart, after the interceptor fix using KEDA-HTTP we were able to achieve much better results which also surpassed manual scale configurations. In our experiments KEDA-HTTP produced the best TPS / Replica across all concurrencies that we tested.
Conclusion
We found out that when pods are heavily loaded, autoscaling with CPU usage autoscales too soon, but KEDA-HTTP autoscaling against the count of pending http requests behaves in a much more stable manner.
KEDA-HTTP also enables us to scale to and from 0 replicas which will further benefit us in our iPaas solution.
Try out Choreo - an internal developer platform designed to accelerate the creation of digital experiences. Build, deploy, monitor, and manage your cloud native applications with ease as you improve developer productivity and focus on innovation.